목표 VU, TPS 설정하기
토독토독의 예상 사용자를 우아한테크코스 8기 지원 예상 인원으로 설정했고, 7기 기준으로 약 3,000명 정도로 가정할 수 있었다.
이 수치를 MAU(월간 사용자 수)라고 본다면, 커뮤니티성 서비스의 DAU(일간 사용자 수)는 보통 10~20% 정도로 잡을 텐데,
부하 테스트를 진행할 예정이니 평균치보다 좀 더 빈번하게 잡아 30%, 900명으로 잡아볼 수 있다.
주로 토론이 핫할 때나 저녁을 먹고 쉴 때 동시 접속자 수가 많을 것으로 예상되고, 이때의 접속 인원을 DAU의 약 10%라고 가정하면 90명 정도가 피크 시간에 동시에 접속한다고 예상할 수 있다.
그럼 목표 TPS는 어떻게 산정해 볼 수 있을까?
일반적으로 DAU 혹은 동시 접속자 수를 기준으로 목표 TPS를 산정할 때, 아래와 같은 방식을 사용할 수 있다고 한다.
- DAU 기반 계산(파레토의 법칙): DAU * 인당 평균 요청 수 / 24 * 3,600초(1시간)
- 피크 시간 동시 접속자 수 기반(리틀의 법칙): 동시 접속자 수 / 응답시간(초) * 요청 수
부하 테스트를 진행하는 것이니 이 중 2번 방법으로 선택하되, 더 보수적으로 동시 접속자 수가 아닌 DAU 900명이 1시간(3,600초) 동안 100회의 요청을 하는 상황으로 가정해 보면 아래와 같이 TPS를 계산할 수 있다.
- 900명 / 3,600초 * 100회 = 25TPS
따라서 피크 시간에 동시에 접속할만한 인원이 90명이고, 점진적으로 늘어날 가능성을 고려해 실 테스트의 목표치는 아래와 같이 설정한다.
- VU: 90명부터 150명까지 점진적으로 증가
- TPS: 25~30TPS
테스트 환경
추가로, 테스트를 진행하는 하드웨어 스펙은 아래와 같았다.
- WAS: AWS EC2 t4g.small(vCPU 2, 메모리 2GB) 1대 (Spring Boot)
- Reverse Proxy: AWS EC2 t4g.nano (Nginx)
- Monitoring: AWS EC2 t4g.small(vCPU 2, 메모리 2GB) 1대 (Prometheus, Grafana, Loki)
- Database: AWS RDS MySQL 8.0 t3.medium Multi-AZ (Writer 사용)
- Test Tool: k6
1차 부하 테스트
스모크 테스트 시나리오에서 가상 유저의 수와 증가 시간 등을 수정해 부하 테스트 시나리오를 재작성했다.
재작성한 시나리오 스크립트를 실행한 결과 아래와 같은 현상을 모니터링할 수 있었다.
1. k6 결과

| 분류 | 수치 |
| 총 요청(http_reqs) | 25,693 |
| 실패요청(http_req_failed) | 195 |
| 평균 응답시간 (Latency) | 2.88s |
| p95 응답시간 (Latency) | 6.45s |
| p99 응답시간 (Latency) | 8.81s |
| 평균 TPS (http_reqs) | 28.001564/s |
이 수치를 해석해 보면,
사용자는 모든 요청에 응답을 받기 위해 평균적으로 2.88초의 시간을 기다려야 했고, 더 길어지는 응답까지 포함한다면 p95, p99 수치로 보았을 때 6.45초, 8.81초까지도 기다려야 한다는 뜻이다.
응답시간은 빠를수록 좋겠지만, 초기 런칭 시점을 기준으로 p95는 1초, p99는 2초 정도가 사용자의 기다림과 인내심에 적합한 수치라고 보았기에, 한참 부족한 수치였다. (고객의 47%는 웹 페이지가 2초 이내에 로드되기를 기대)
평균 TPS는 목표치였던 25~30TPS 사이값이지만, 사용자는 긴 응답시간을 기다려야 하기 때문에 개선이 필요하다.
2. k6 proemetheus monitoring
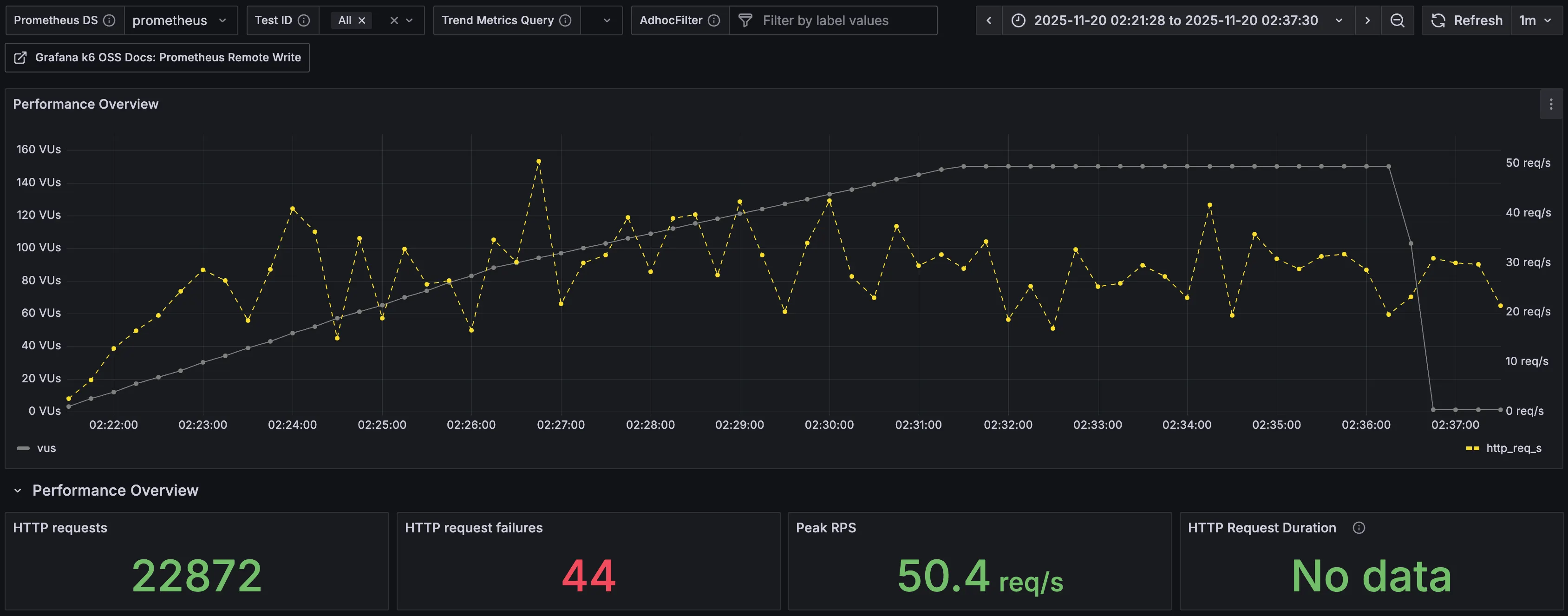
| 분류 | 수치 |
| 총요청(HTTP requests) | 22,872 |
| 실패요청(HTTP request failures) | 44 |
| Peak RPS(TPS) | 50.4 req/s |
k6 결과의 수치와는 살짝 다른데, k6 결과의 수치는 클라이언트 측에서 기록한 수치이고, 이 수치는 prometheus에서 기록한 수치이므로 서버에서 기록한 수치이기 때문이다.
클라이언트에서 요청을 보냈더라도 서버에서 수신하고 처리한 요청의 수는 다를 수 있다.
혹은 모니터링 시스템에서 기록할 수 있는 계층까지 도달하지 못하고 중간에 실패했을 가능성도 있다.
여기서 확인할 수 있는 Peak RPS(TPS)는 말 그대로 최대 처리 능력을 의미한다.
순간적으로 치솟은 값인데, 이 시간대의 특이점이 있는지 확인해 보면 좋을 것 같다.
3. Tomcat
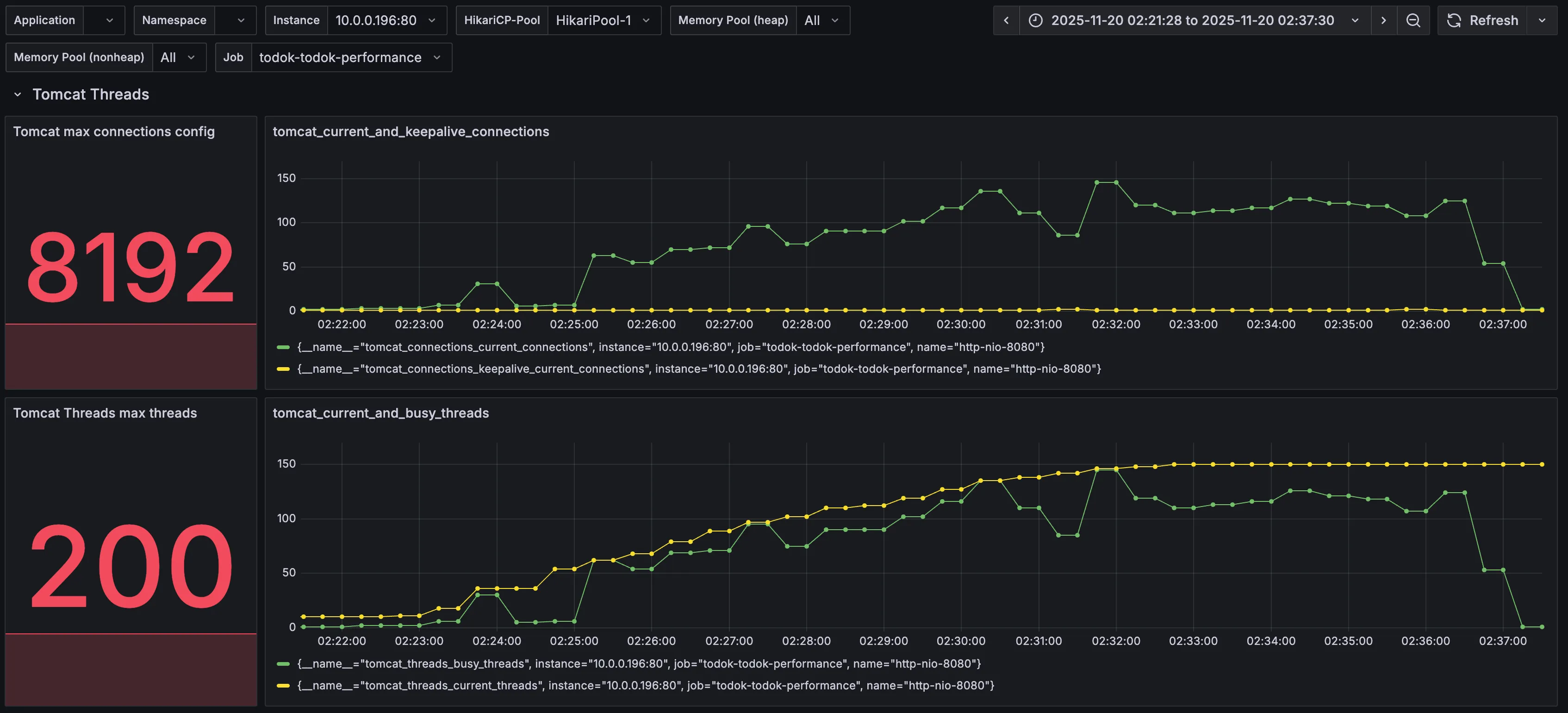
| 분류 | 수치 | 의미 |
| Tomcat max threads | 200 | 서버가 동시에 처리할 수 있는 스레드의 수 |
| current busy threads | 최대 150 | 현재 요청 처리에 사용 중인 스레드의 수 |
| current threads | 최대 150 | 현재 생성된 총 스레드의 수(busy + idle) == (사용중 + 유휴) |
별도로 설정을 해주지 않았기 때문에 max threads가 기본 값인 200으로 설정되었다.
busy threads가 VU의 최댓값인 150까지 증가한 뒤 멈춰있다는 것은 다른 요인에 의해 스레드가 멈춰있다는 것을 의미한다.
그 다른 요인을 찾아야 한다.
4. DBCP(Database Connection Pool)

| 분류 | 수치 | 의미 |
| Max Connections | 10 | 커넥션 풀이 가질 수 있는 최대 커넥션(연결) 수 == 서버가 동시에 처리할 수 있는 DB 요청 상한선 |
| Timeout Connection Count | 28 | 커넥션을 얻기 위해 기다렸지만, 설정된 대기 시간을 초과하여 요청이 실패한 횟수 |
| Connections - Active | 10 | 현재 DB 쿼리/작업을 수행 중(사용 중)인 커넥션 수 == 현재 DB 요청을 처리 중인 스레드의 수 |
| Connections - Idle | - | 현재 사용되지 않고 (유휴 상태로) 대기 중인 커넥션의 수, 다음 요청이 오면 즉시 할당될 준비가 되어 있음 |
| Connections - Pending | 138 | 커넥션을 할당받기 위해 대기 중인 요청(스레드)의 수 |
| Connection Acquire Time | 최대 1.6 | 커넥션을 풀에서 가져오는 데 걸린 최대 시간, 높을수록 클라이언트 요청이 DB 작업 시작 전에 오래 기다림 |
DBCP 역시 별도로 설정해주지 않았으므로 기본값인 10으로 설정되어 있다.
Timeout Connection Count가 28이라는 것은 28개의 요청이 너무 오래 대기하여 기다리다가 DB Connection Timeout으로 실패했음을 의미한다.
Connections 그래프를 확인해 보면, 10개의 커넥션을 모두 사용해 대기(Pending)가 최대 138개까지 늘어난 것을 볼 수 있다.
DB 커넥션을 얻기 위한 대기가 있다는 것은 DB에 병목이 존재한다는 뜻이다.
총 150명의 VU 중 10명은 DB 커넥션을 얻었고, 138명은 커넥션을 얻기 위해 대기, 28명은 대기하다가 커넥션을 얻지 못해 타임아웃을 받았다.
5. CPU & I/O Time

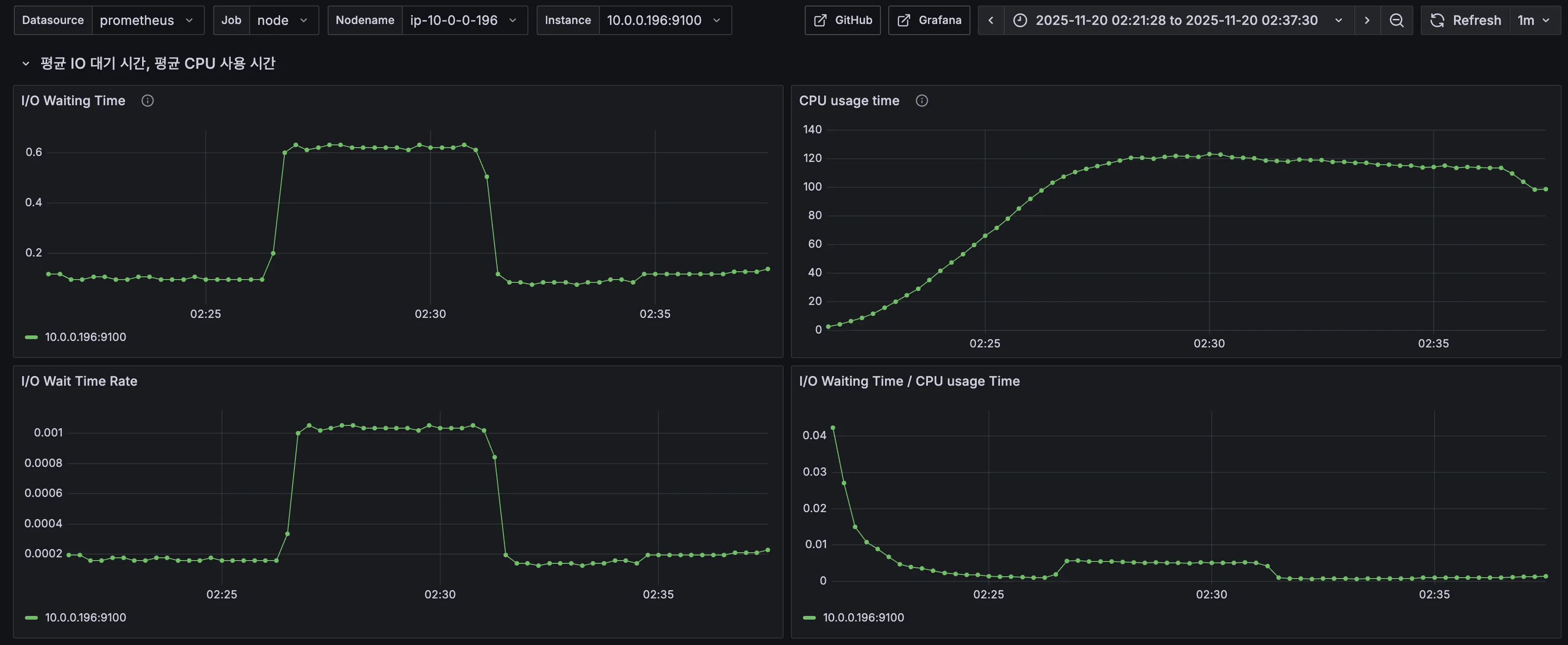
같은 시점의 CPU와 I/O Time 모니터링에서는 큰 특이점이 보이지 않았다.
6. k6 로그
k6-test | running (04m23.9s), 079/150 VUs, 1406 complete and 0 interrupted iterations
k6-test | default [ 29% ] 079/150 VUs 04m23.9s/15m00.0s
k6-test | time="2025-11-19T17:25:42Z" level=info msg="\n❌ Access Token을 획득하지 못했습니다. 테스트 중단" source=console
k6-test | running (07m05.9s), 115/150 VUs, 2407 complete and 0 interrupted iterations
k6-test | default [ 47% ] 115/150 VUs 07m05.9s/15m00.0s
k6-test | time="2025-11-19T17:28:24Z" level=info msg="\n❌ 로그인 실패. 테스트 중단" source=console
테스트가 진행되면서 클라이언트 측에서 찍힌 로그인데, 아마 회원가입/로그인 시 토큰을 획득하지 못해 로그인이 실패한 것으로 추정된다.
서버 로그도 확인해보면 중복된 토큰 발급 요청이 확인되는데 이것과 연관이 있을 것 같다.
7. 서버 로그
[2025-11-20 02:28:24:20711179] [http-nio-8080-exec-360] WARN [todoktodok.backend.global.exception.GlobalExceptionHandler.handleConcurrentModificationException:114] - client: [54.180.146.78] -> server: [172.18.0.2] [ERROR] 중복된 리프레시 토큰 발급 요청입니다: memberId = 18837
[2025-11-20 02:28:24:20711300] [http-nio-8080-exec-324] WARN [todoktodok.backend.global.exception.GlobalExceptionHandler.handleBadRequestException:38] - client: [54.180.146.78] -> server: [172.18.0.2] [ERROR] 해당 토론방에 있는 댓글이 아닙니다: discussionId = 2580, commentId = 12088
[2025-11-20 02:28:24:20711610] [http-nio-8080-exec-341] ERROR [todoktodok.backend.notification.infrastructure.FcmPushNotifier.sendPush:70] - client: [54.180.146.78] -> server: [172.18.0.2] Fail sending message to FCM : cause = 해당 회원에게 전송할 fcmToken이 없습니다, recipientId = 1288
[2025-11-20 02:28:25:20711630] [http-nio-8080-exec-325] WARN [todoktodok.backend.global.exception.GlobalExceptionHandler.handleNotFoundException:47] - client: [54.180.146.78] -> server: [172.18.0.2] [ERROR] 해당 댓글을 찾을 수 없습니다: commentId = 13344
[2025-11-20 02:31:41:20908280] [http-nio-8080-exec-343] WARN [todoktodok.backend.global.exception.GlobalExceptionHandler.handleBadRequestException:38] - client: [54.180.146.78] -> server: [172.18.0.2] [ERROR] 이미 가입된 이메일입니다: email = test**************
'이미 가입된 이메일입니다', '중복된 리프레시 토큰 발급 요청입니다'와 같은 로그는 k6 로그에서 확인됐던 것과 같은 로직 문제일 것 같다.
'해당 댓글을 찾을 수 없다'는 로그와 '해당 토론방에 있는 댓글이 아닙니다'는 로그는 시나리오 상 데이터 일관성 문제가 있는 것으로 예상되니 시나리오를 수정하도록 한다.
'해당 회원에게 전송할 fcmToken이 없습니다'는 로그는 더미 데이터 준비 시 fcmToken은 준비하지 않았기 때문일 것이다.
하지만 이런 로그들이 DB 병목의 주요 원인은 아닐 것 같다.
8. 결론 및 해결책
DB 병목이 응답시간을 지연시키는 데 가장 큰 원인이라고 생각된다.
이를 해결하기 위해, 다음 테스트에서는 DBCP의 설정을 조정해 보고, Acquire Time(DB 커넥션을 풀에서 가져오는 시간)을 최소화해 응답시간 지연을 해결해 보도록 한다.
추가로, 비즈니스 로직 상 문제가 있는 것으로 확인된 로그들도 코드 수정을 통해 해결해 본다.
2차 부하 테스트
1. 변경점
- 비즈니스 로직: 서버 로그에서 확인되었던 '해당 회원에게 전송할 fcmToken이 없습니다'를 해결하기 위해 fcmToken이 없는 회원(사전 더미데이터로 준비한 회원)은 ealry return 하도록 로직을 수정했다.
- 시나리오 스크립트: 서버 로그에서 확인됐던 '해당 댓글을 찾을 수 없다', '해당 토론방에 있는 댓글이 아닙니다'를 해결하기 위해 실제 사용자의 행동 흐름처럼 토론방에서 댓글 목록을, 대댓글 목록을 조회한 뒤 실제 존재하는 댓글, 대댓글을 선택하여 좋아요를 하도록 수정했다.
- 설정값: DBCP 병목 해소를 위해 hikari maximum-pool-size를 10에서 50으로 수정했다.
2. k6 결과

| 분류 | 직전 수치 | 현재 수치 |
| 총 요청(http_reqs) | 25,693 | 23,877 |
| 실패요청(http_req_failed) | 195 | 3 |
| 평균 응답시간 (Latency) | 2.88s | 3.14s |
| p95 응답시간 (Latency) | 6.45s | 12.26s |
| p99 응답시간 (Latency) | 8.81s | 20.82s |
| 평균 TPS (http_reqs) | 28.001564/s | 25.894672/s |
결과가 좋아질 것으로 기대하고 maximum-pool-size를 늘렸는데, 오히려 상태가 더 안 좋아졌다.
3. k6 prometheus monitoring
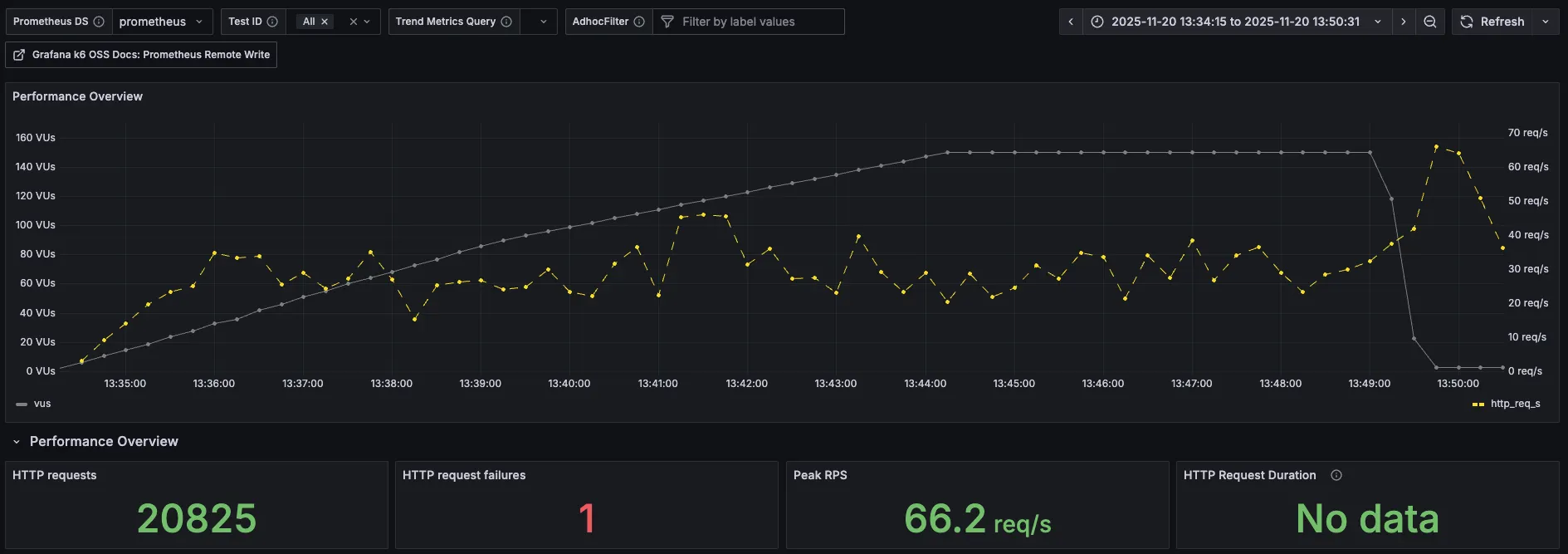
| 분류 | 직전 수치 | 현재 수치 |
| 총요청(HTTP requests) | 22,872 | 20,825 |
| 실패요청(HTTP request failures) | 44 | 1 |
| Peak RPS(TPS) | 50.4 req/s | 66.2 req/s |
Peak RPS가 직전보다 높아졌지만, 총 처리량도 줄었고 응답시간도 늘었기 때문에 유의미한 결과가 아니라고 생각한다.
4. Tomcat
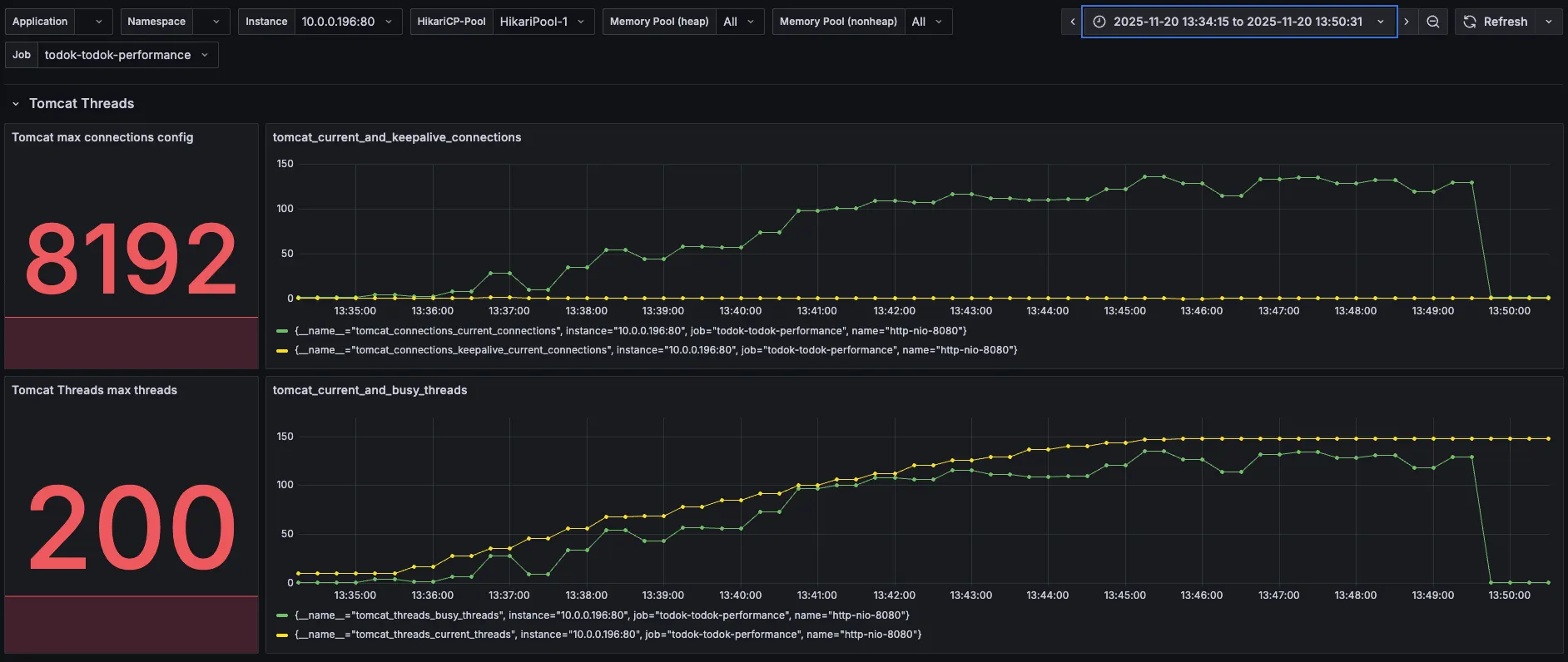
| 분류 | 직전 수치 | 현재 수치 |
| Tomcat max threads | 200 | 200 |
| current busy threads | 최대 150 | 최대 150 근접 |
| current threads | 최대 150 | 최대 150 근접 |
직전과 크게 다를 바 없다. 여전히 병목이 존재한다.
5. DBCP

| 분류 | 직전 수치 | 현재 수치 |
| Max Connections | 10 | 50 |
| Timeout Connection Count | 28 | 0 |
| Connections - Active | 10 | 50 |
| Connections - Pending | 138 | 89 |
| Connection Acquire Time | 최대 1.6 | 최대 1.57 |
maximum-pool-size를 최대 50까지 늘렸으니 max connections는 50으로 증가한 것을 확인할 수 있다.
timeout connection count는 0으로 줄었지만, 여전히 Pending 값이 89개이고
풀에서 커넥션을 얻기 위한 Acquire Time은 1.57이다.
6. CPU & I/O Time


직전과 크게 다를 바가 없다..!
7. k6 로그
k6-test | running (04m06.9s), 074/150 VUs, 1185 complete and 0 interrupted iterations
k6-test | default [ 27% ] 074/150 VUs 04m06.9s/15m00.0s
k6-test | time="2025-11-20T04:38:17Z" level=info msg="\n❌ 로그인 실패. 테스트 중단" source=console
k6-test | running (05m36.9s), 097/150 VUs, 1745 complete and 0 interrupted iterations
k6-test | default [ 37% ] 097/150 VUs 05m36.9s/15m00.0s
k6-test | time="2025-11-20T04:39:48Z" level=warning msg="Request Failed" error="Get \"http://43.202.235.126/api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94\": request timeout"
로그인 실패는 1차 테스트 때와 동일한 현상이다.
이번 테스트에서는 토론방 검색 API에서 갑자기 request timeout이 발생했다.
8. 서버 로그
[2025-11-20 13:37:38] [http-nio-8080-exec-26] ERROR [t.b.n.infrastructure.FcmPushNotifier:76] - client: [54.180.146.78] -> server: [172.18.0.2] Fail sending message to FCM : cause = FirebaseApp with name [DEFAULT] doesn't exist. , recipientId = 26182
[2025-11-20 13:38:17] [http-nio-8080-exec-50] WARN [t.b.g.e.GlobalExceptionHandler:114] - client: [54.180.146.78] -> server: [172.18.0.2] [ERROR] 중복된 리프레시 토큰 발급 요청입니다: memberId = 26363
로그인 실패와 연관된 중복 리프레시 토큰 발급 요청 로그와 fcm 전송 실패 로그가 확인된다.
DB 병목과는 전혀 관련이 없다.
9. 결론 및 해결책
여전히 DB 병목이 원인으로 보인다.
토론방 검색 API의 request timeout을 기억해 두고, Pending 상태인 89개까지 처리할 수 있는지 maximum-pool-size를 50에서 100으로 조정한 뒤 다시 테스트해 보도록 한다.
3차 부하 테스트
1. 변경점
- 설정값: DBCP 병목 해소를 위해 hikari maximum-pool-size를 50에서 100으로 수정했다.
2. k6 결과
| 분류 | 직전 수치 | 현재 수치 |
| 총 요청(http_reqs) | 23,877 | 22,395 |
| 실패요청(http_req_failed) | 3 | 95 |
| 평균 응답시간 (Latency) | 3.14s | 3.4s |
| p95 응답시간 (Latency) | 12.26s | 19.71s |
| p99 응답시간 (Latency) | 20.82s | 27.28s |
| 평균 TPS (http_reqs) | 25.894672/s | 24.265373/s |
이번에도 수치가 오히려 더 악화되었다.
특이한 점은 API 목록에서 토론방 검색 성공이 74%만 수행되었다. 2차 k6 로그에서 토론방 검색 API에 request timeout이 발생한 점과 연결 지어볼 수 있을 것 같다.
3. k6 proemetheus monitoring
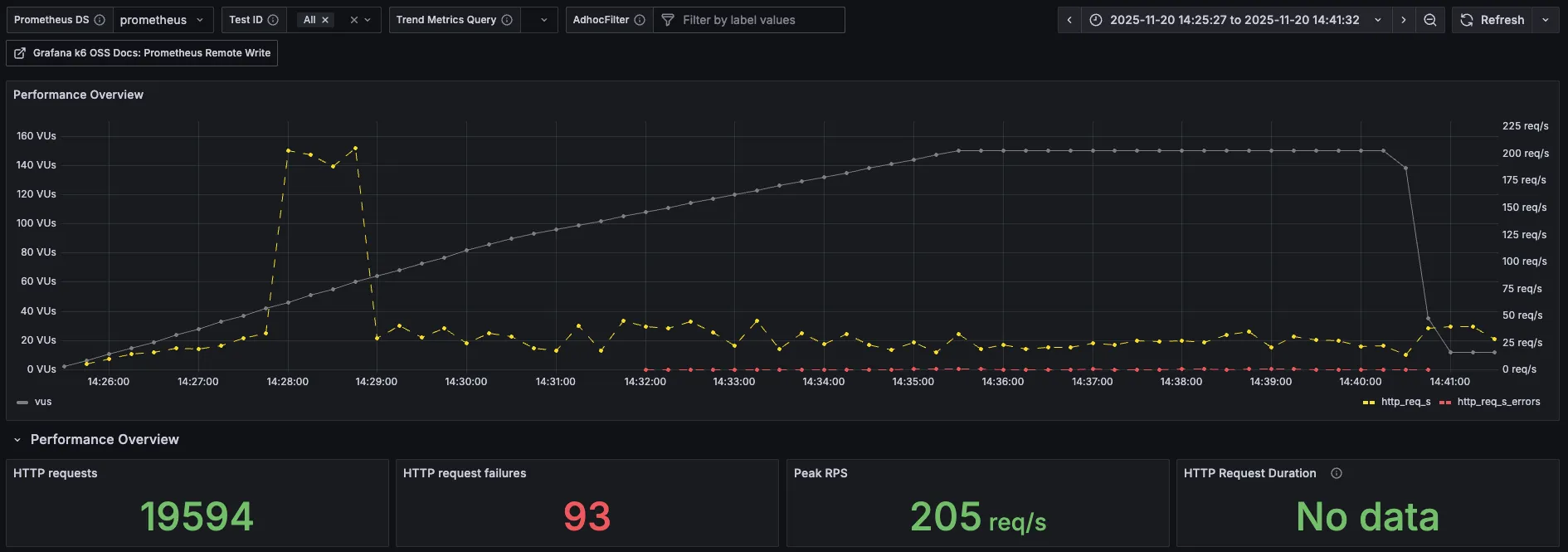
| 분류 | 직전 수치 | 현재 수치 |
| 총요청(HTTP requests) | 20,825 | 19,594 |
| 실패요청(HTTP request failures) | 1 | 93 |
| Peak RPS(TPS) | 66.2 req/s | 205 req/s |
이번에도 역시 Peak RPS(TPS)는 증가했지만, 무의미하다고 생각된다.
Peak를 찍은 이후로 서버로 들어오는 요청이 아주 적어졌고, 요청 실패도 발생했다.
요청 실패는 아마 토론방 검색 API 실패로 찍히는 값이 아닐까 생각된다.
4. Tomcat
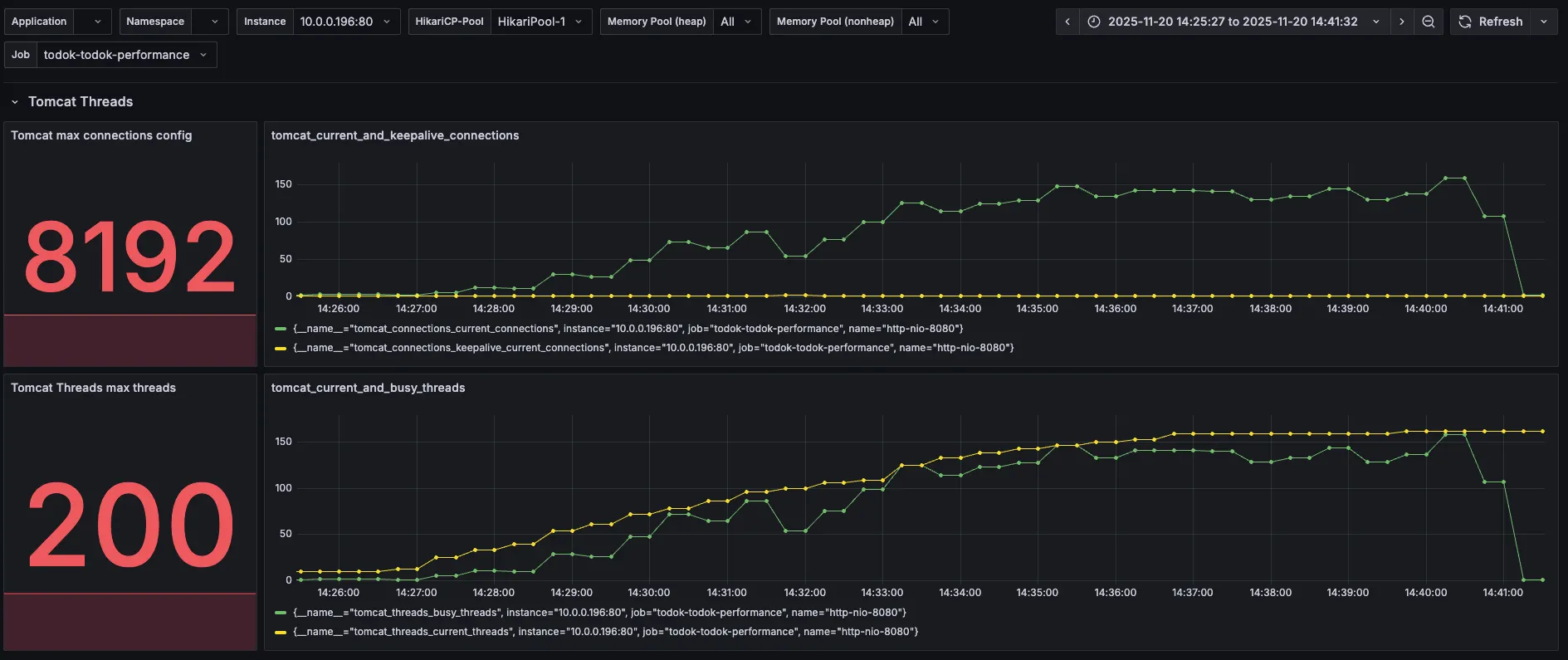
| 분류 | 직전 수치 | 현재 수치 |
| Tomcat max threads | 200 | 200 |
| current busy threads | 최대 150 근접 | 150 살짝 초과 |
| current threads | 최대 150 근접 | 150 살짝 초과 |
150을 초과한 점이 살짝 다르긴 하지만, 직전 수치와 크게 다를 바 없어 보인다.
5. DBCP
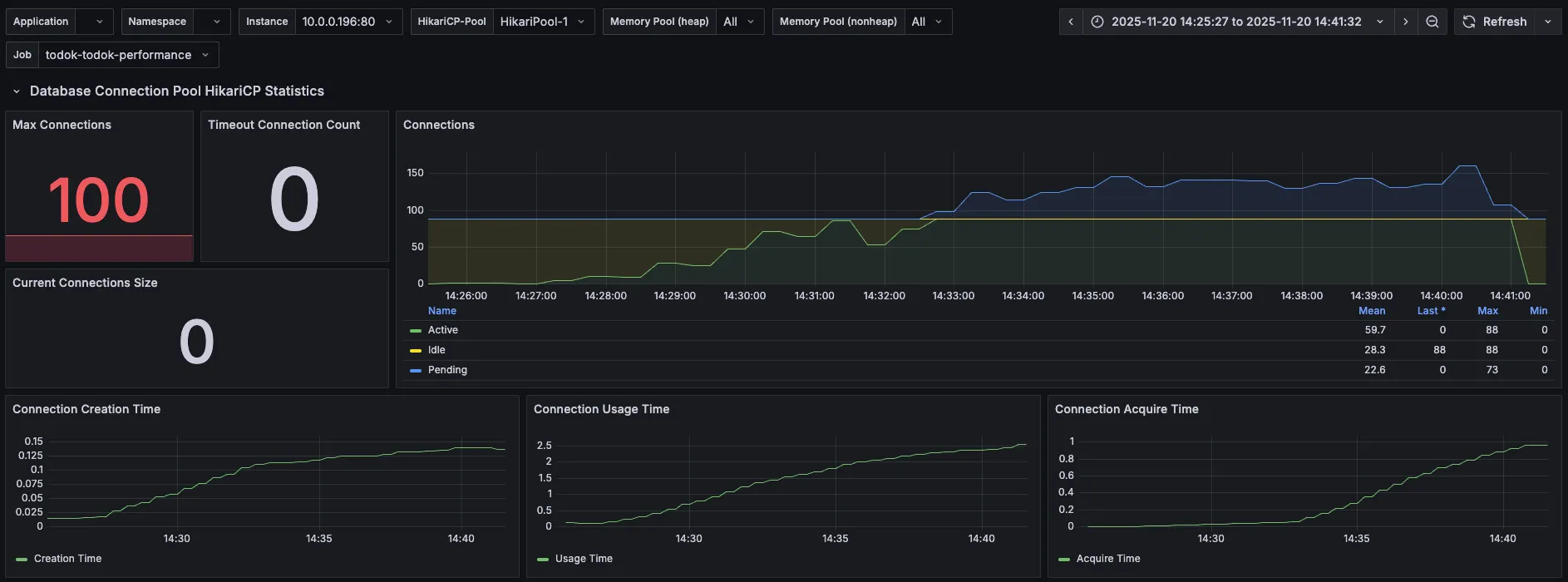
| 분류 | 직전 수치 | 현재 수치 |
| Max Connections | 50 | 100 |
| Timeout Connection Count | 0 | 0 |
| Connections - Active | 50 | 88 |
| Connections - Pending | 89 | 73 |
| Connection Acquire Time | 최대 1.57 | 최대 1 |
maximum-pool-size를 100으로 늘렸으니 max connections도 100으로 늘어났다.
그런데 왜 Active는 max connections인 100까지 증가하지 않고 88까지만 증가했을지 의문이다.
Acquire Time이 줄긴 했지만 여전히 Pending 상태가 많다.
커넥션 풀의 크기를 늘려서 DB 커넥션을 확보하기 위한 대기 시간은 줄었으나, 100개 가까이 되는 커넥션이 동시에 쿼리를 실행하면서 DB 서버에 부하가 가중된 것은 아닐까 생각된다.
그러니 개별 쿼리 실행 시간도 체크해 보도록 한다.
응답시간 지연의 주요 원인이 DB 커넥션 대기에서 개별 쿼리 실행 시간으로 이동한 것 아닐까라고 추측해 본다.
6. CPU & I/O Time

이번에도 크게 특이점이 존재하지 않았다.
7. API별 응답시간
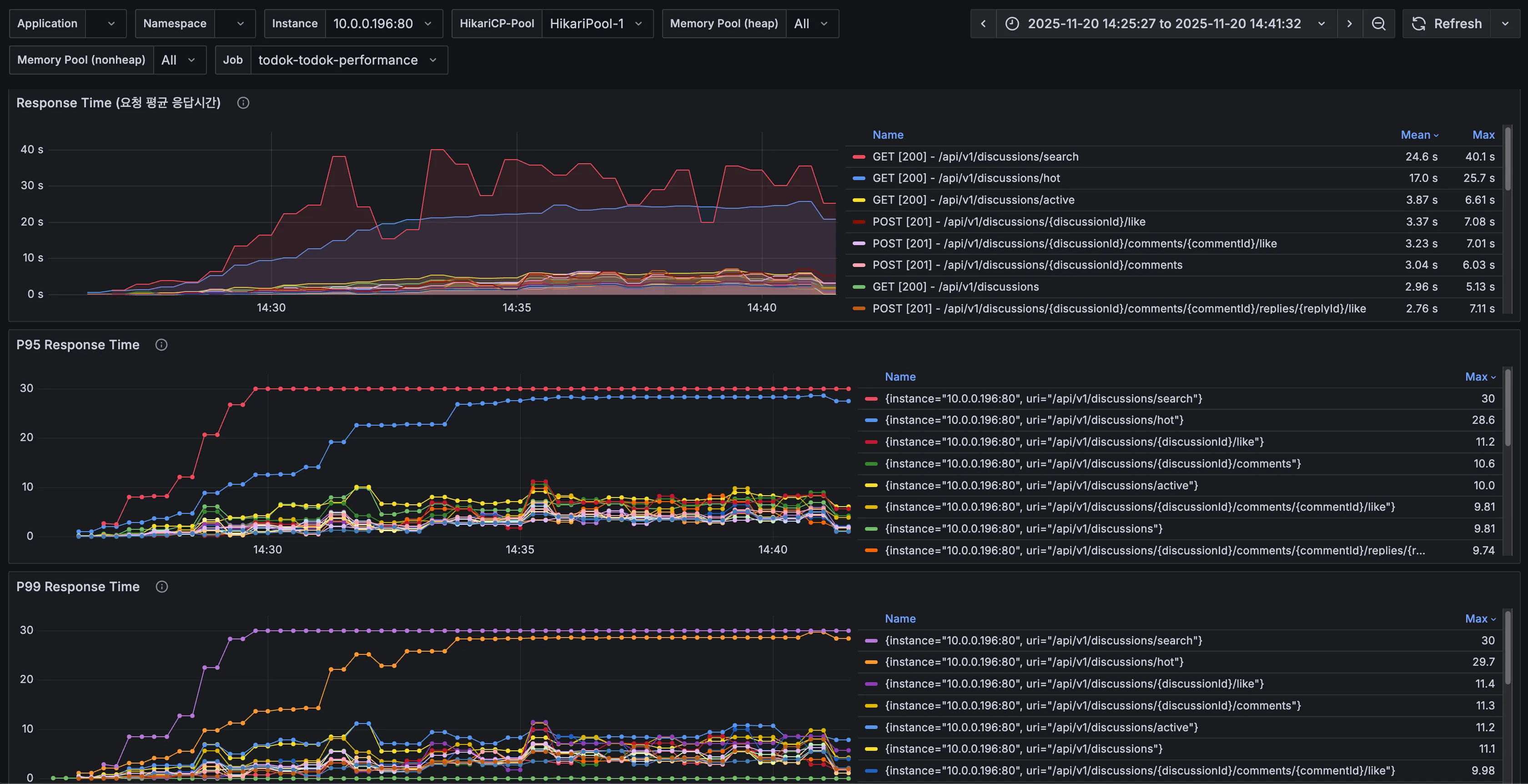
DBCP의 측정 내용을 토대로 이번에는 API별 응답시간도 확인해 보았다.
직전 테스트에서 갑자기 request timeout이 발생했던 토론방 검색(/api/v1/discussions/search)의 응답시간이 가장 느린 것을 확인할 수 있다.
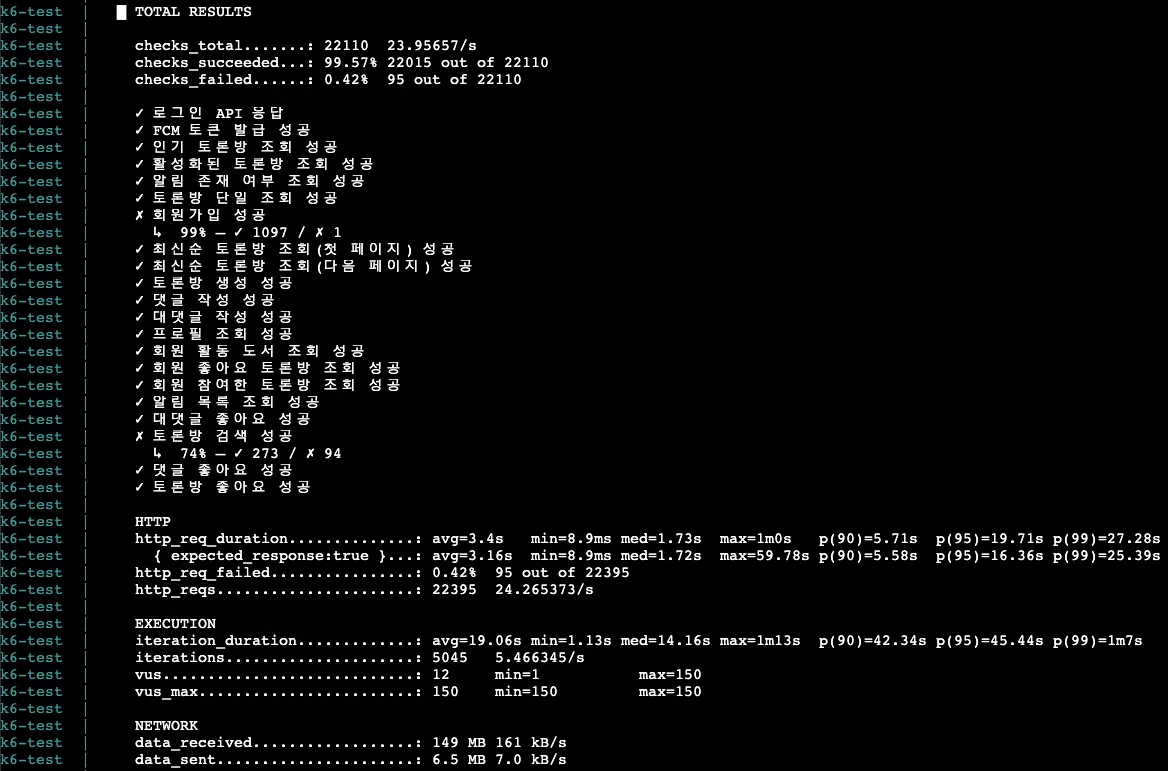
8. k6 로그
k6-test | running (05m15.9s), 093/150 VUs, 1581 complete and 0 interrupted iterations
k6-test | default [ 35% ] 093/150 VUs 05m15.9s/15m00.0s
k6-test | time="2025-11-20T05:30:40Z" level=warning msg="Request Failed" error="Get \"http://43.202.235.126/api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94\": request timeout"
k6-test |
k6-test | running (05m16.9s), 093/150 VUs, 1581 complete and 0 interrupted iterations
k6-test | default [ 35% ] 093/150 VUs 05m16.9s/15m00.0s
k6-test |
k6-test | running (05m17.9s), 093/150 VUs, 1585 complete and 0 interrupted iterations
k6-test | default [ 35% ] 093/150 VUs 05m17.9s/15m00.0s
k6-test | time="2025-11-20T05:30:41Z" level=warning msg="Request Failed" error="Get \"http://43.202.235.126/api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94\": request timeout"
k6-test | time="2025-11-20T05:30:41Z" level=warning msg="Request Failed" error="Get \"http://43.202.235.126/api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94\": request timeout"
직전 테스트에서는 1회만 확인됐던 request timeout이 이번에는 다수(약 94회) 확인됐다.
이 로그가 찍히기 시작한 시점은 VU 90명 달성 이후(즉 테스트 후 5분이 지난 시점)이고, 지속적으로 토론방 검색 API에 대한 요청만 주기적으로 request timeout이 발생했다.
9. 서버 로그
[2025-11-20 14:36:35] [http-nio-8080-exec-101] ERROR [t.b.n.infrastructure.FcmPushNotifier:76] - client: [54.180.146.78] -> server: [172.18.0.2] Fail sending message to FCM : cause = FirebaseApp with name [DEFAULT] doesn't exist. , recipientId = 24191
[2025-11-20 14:31:28] [http-nio-8080-exec-69] ERROR [o.h.e.jdbc.spi.SqlExceptionHelper:150] - client: [54.180.146.78] -> server: [172.18.0.2] Duplicate entry 'test1284@gmail.com' for key 'member.email'
이번에도 직전 테스트와 동일하게 FCM, 인증 관련 에러 로그가 찍혔지만, 응답시간 지연과는 무관한 것 같다.
10. Nginx 로그
2025/11/20 06:54:37 [error] 22#22: *422490 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 54.180.146.78, server: todoktodok.com, request: "GET /api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94 HTTP/1.1", upstream: "http://10.0.0.196:80/api/v1/discussions/search?keyword=%EC%9E%90%EB%B0%94", host: "43.202.235.126"
요청이 Nginx를 통과해서 WAS에 도달했지만, WAS가 DB에서 느린 쿼리를 실행하느라 응답을 기다리는 시간이 Nginx의 Upstream Timeout 설정보다 길었기 때문에 Nginx가 먼저 연결을 끊고 오류를 기록한 것으로 보인다.
Nginx의 proxy_read_timeout 값은 별도로 설정한 적이 없기 때문에 기본값인 60초로 설정되어 있을 것이다.
11. 결론 및 해결책
풀에서 DB 커넥션을 얻기 위한 Acquire Time은 줄어든 것으로 보아 커넥션 대기 병목은 조금 해소가 된 것 같다.
하지만 100개 가까이 되는 커넥션이 동시에 쿼리를 실행하면서 DB 서버에 부하가 가고, 개별 쿼리 실행 시간이 증가했을 것으로 예상된다.
k6 결과와 로그, 요청별 응답시간을 토대로 '토론방 검색 API'에 있는 쿼리 중 하나가 Slow query일 가능성이 매우 높다.
그다음으로는 '인기 토론방 조회 API'도 토론방 검색 못지않게 응답시간이 길기 때문에 두 API에서 Slow query를 찾아보도록 한다.
3편에서 이어서..!
https://ju-heee.tistory.com/68
내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 3 (부하 테스트 4~5차)
4차 부하 테스트1. 3차 테스트를 토대로 확인한 점AWS의 RDS 파라미터를 설정하면 Slow Query 로그를 확인할 수 있다.3차 테스트 기간 동안 발생한 Slow Query를 확인해보니 아래 쿼리들이 확인되었다.#
ju-heee.tistory.com
'study > 우아한테크코스' 카테고리의 다른 글
| 내가 가진 색깔의 근거를 찾는 여정 - 하드웨어 스펙을 고려한 성능 테스트 진행기 4 (부하 테스트 6~10차) (2) | 2025.12.03 |
|---|---|
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 3 (부하 테스트 4~5차) (0) | 2025.12.01 |
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 1 (시나리오 수정, 스모크 테스트) (0) | 2025.11.28 |
| 2025 WOOWACON(우아콘) 후기 (2) | 2025.10.29 |
| 우아한테크코스 7기 백엔드 레벨2 회고 (0) | 2025.06.29 |