6~9차 부하테스트
| 차수 | 분류 | 직전 수치 | 바꾼 수치 | 이유 |
| 6차 | hikari maximum-pool-size | 100 | 150 | Active 88 + Pending 35 = 총 123이므로 이 값보다 우회하도록 설정 |
| Tomcat max-threads | 200 | 300 | DB pool size가 늘어났으므로 WAS가 여유있게 처리할 수 있도록 스레드 수를 함께 조정 | |
| 7차 | hikari maximum-pool-size | 150 | 120 | Active 88 + Pending 35 = 총 123이므로 이 값과 비슷한 수준으로 설정 |
| Tomcat max-threads | 300 | 250 | DBCP에 맞게 조정 | |
| 8차 | hikari maximum-pool-size | 120 | 110 | 더 낮춰볼까..? 😭 |
| Tomcat max-threads | 250 | 220 | DBCP에 맞게 조정 | |
| 9차 | hikari maximum-pool-size | 110 | 100 | 가장 성능이 좋았던 5차와 비슷하게 다시 시도 |
| Tomcat max-threads | 220 | 200 | DBCP에 맞게 조정 |
6차부터 9차까지는 단순히 hikari maximum-pool-size와 Tomcat max-threads를 조정해보기만 했는데,
오히려 수치가 악화될 뿐 전혀 좋아지지 않았다.
심지어 가장 성능이 좋았던 5차와 같은 수치로 다시 테스트를 해봤는데, 이 마저도 안 좋은 수치가 나와서 이해가 가지 않았다.
5차와 비교하여 9차에 점진적으로 쌓인 데이터 때문인 걸까? 라고 의문을 가져보기도 했다.
갑자기 연결이 되지 않는 RDS
9차 테스트까지 마치고 다음날, 데이터를 리셋하고 다시 테스트해보려고 MySQL Workbench로 DB에 접속하자 아래와 같은 오류 문구가 뜨며 연결이 되지 않았다.
Your connection attempt failed for user 'admin' to the MySQL server at turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com:3306:
Unable to connect to localhost
Please:
1 Check that MySQL is running on address turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com
2 Check that MySQL is reachable on port 3306 (note: 3306 is the default, but this can be changed)
3 Check the user admin has rights to connect to turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com from your address (MySQL rights define what clients can connect to the server and from which machines)
4 Make sure you are both providing a password if needed and using the correct password for turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com connecting from the host address you're connecting from
워크벤치만 접속이 안되는 건가? 하는 생각에 DBeaver로 접속을 시도해봤는데, 여기서는 Too many connections 라는 오류 메시지를 확인할 수 있었다.
워크벤치나 디비버 같은 클라이언트로 접속이 안되는 거라면 SSH로는 접속이 가능한지 확인해야 했다.
RDS 서버가 private subnet에 위치하고 있었기 때문에 public subnet에 위치한 서버를 Bastion Host로 통해서 접속해보았다.
우리는 개발 서버가 public subnet에 위치하고 있었고, 개발 서버에서 RDS DB 서버로 네트워크 연결은 되는지 아래 명령어로 먼저 시도해보았다.
# 네트워크 연결 시도
nc -vz turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com 3306
# 성공 메시지!
Connection to turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com (10.0.101.116) 3306 port [tcp/mysql] succeeded!
네트워크 연결에는 문제가 없다는 것이 확인되어서, 개발 서버에 MySQL Client를 설치하고 RDS에 접속을 시도했더니, 정상적으로 접속이 되었다.
# 패키지 목록 업데이트
sudo apt update
# MySQL 클라이언트만 설치
sudo apt install mysql-client -y
# RDS 접속 명령 실행
mysql -h turip-bombom-todoktodok-instance-1.cqsc6pyqhwww.ap-northeast-2.rds.amazonaws.com -u admin -p
RDS에 기본으로 설정된 max-connections가 있다고?
디비버로 접속했을 때 확인했던 Too many connections 를 토대로 SHOW PROCESSLIST; 명령어로 현재 프로세스를 확인했다.
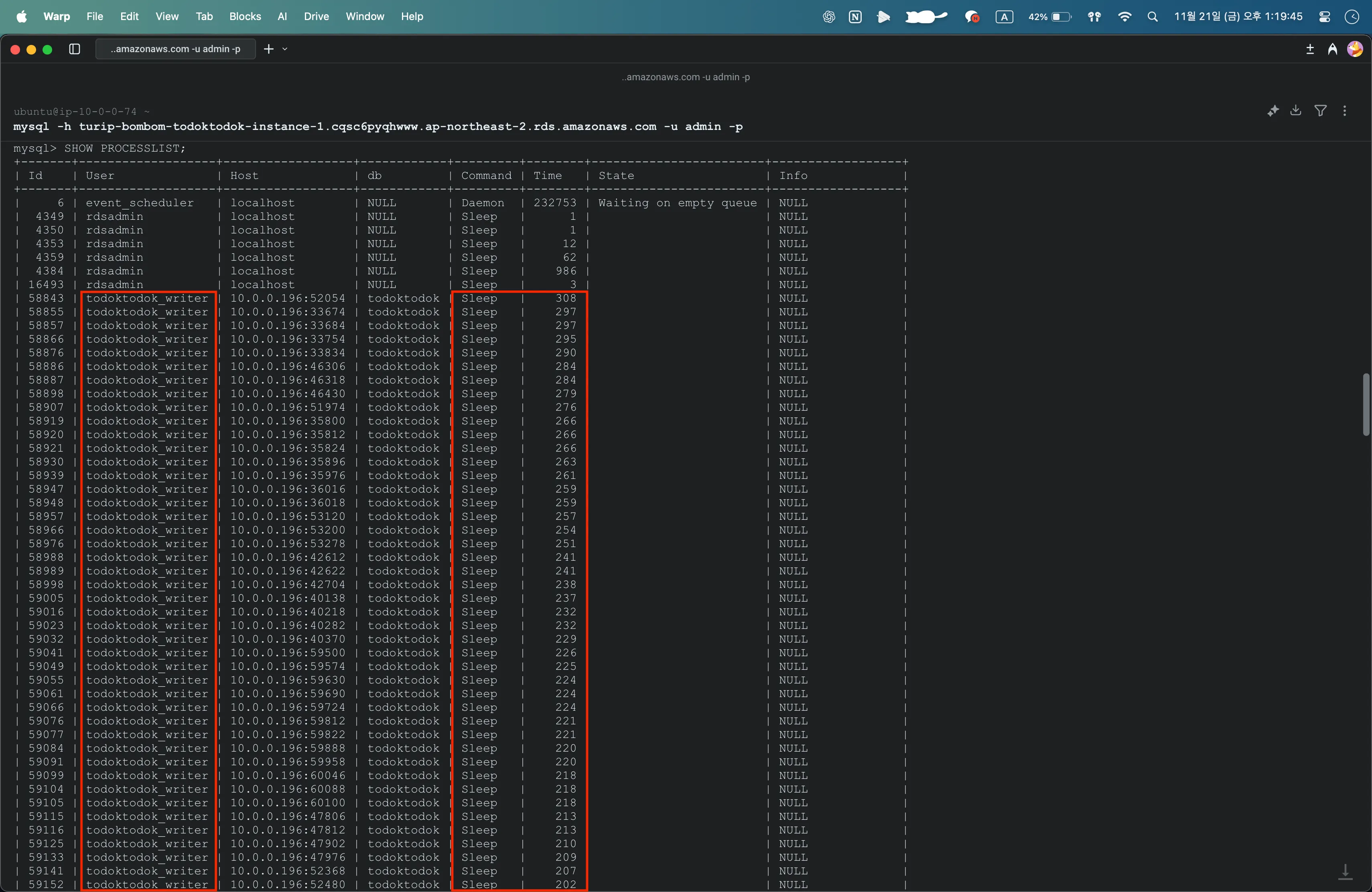
이게 무슨 일..? 수많은 프로세스가 유휴(Sleep) 상태였다.
3차 이후로 hikari maximum-pool-size를 계속 100 이상으로 설정했었다.
minimum-idle이나 idle-timeout 값을 따로 설정해주지 않았었기 때문에 한 번 연결된 connection들이 끊어지지 않고 유휴 상태에 머물러 있는 것이었다.
minimum-idle 값은 설정하지 않는다면 maximum-pool-size와 동일한 값으로 설정이 되고,
idle-timeout값은 8시간이 기본값이라고 한다.
게다가, RDS는 인스턴스의 타입 메모리 크기에 따라 max_connections를 기본으로 설정해주고 있다고 한다.
(RDS가 아니라면 MySQL의 max_connections 기본값은 151이다.)
우리 RDS 인스턴스 타입은 t3.medium이었고, 명령어를 통해 확인해보니 기본으로 설정된 max_connections는 90개였다.
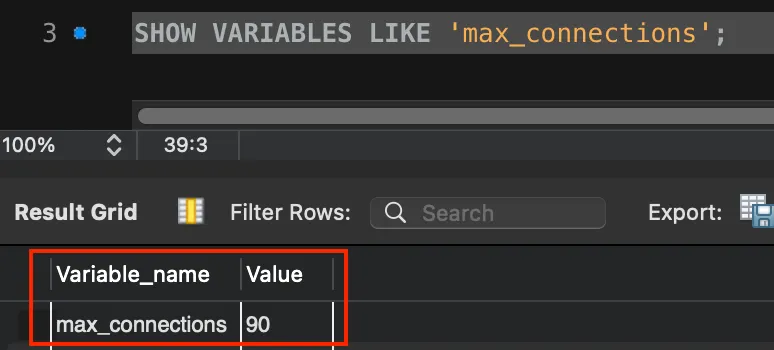
3차 부하테스트 때 hikari maximum-pool-size를 100으로 설정해주었음에도 왜 Active 값이 88 까지만 느는지, 그 의문이 풀리는 순간이었다.
파라미터 그룹을 통해 max_connections를 조정해줄 수는 있지만, 이 하드웨어 스펙에서 AWS가 계산한 최적값보다 높게 설정한다면 메모리 부족 현상을 겪을 수 있겠다고 생각했기에 이 값 자체를 조정하지 않았다.

실제로 DBCP 모니터링 그래프에서도 Idle 연결이 장시간 88개에 고정되어 있던 모습을 확인할 수 있었다.

유휴 연결 관리 최적화
우선 장시간 유휴 상태인 프로세스들을 강제 종료해주었다.
그러니 MySQL 워크벤치로 접속이 가능해졌다!
AWS에서 t3.medium 하드웨어 스펙에 적절한 max-connections 값이 90이라고 설정해두었으니,
이를 토대로 WAS가 DB 서버에 연결할 maximum-pool-size는 90보다 낮은 값인 80으로 하향 조정했다.
90까지 꽉 채우지 않은 이유는 워크벤치나 디비버같은 외부 클라이언트 툴에서도 접속이 가능해야 했으므로..!
추가로, 유휴 상태의 연결들도 관리해주기 위해서 minimum-idle값을 5로 명시적으로 설정해주었다.
idle-timeout 값 또한 기본값 8시간이 아닌 10분으로 조정하여 풀에 있는 연결을 효율적으로 재사용할 수 있도록 했다.
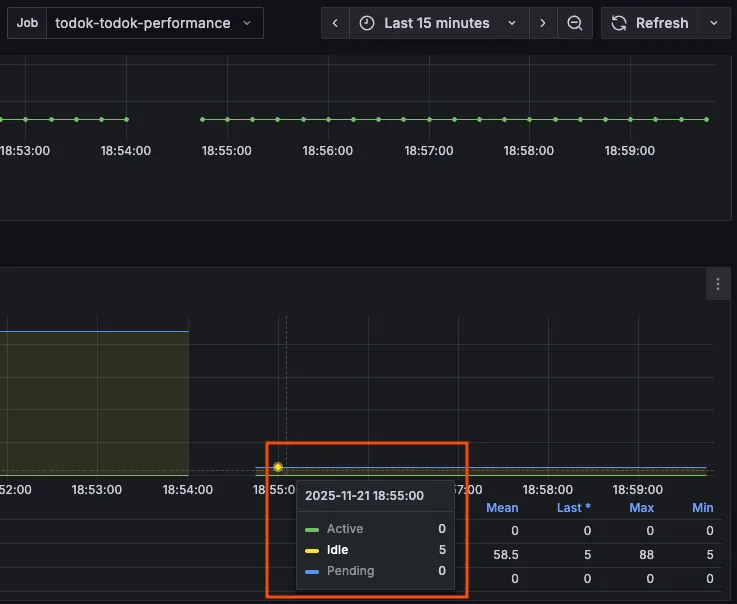
설정 후 Idle 값이 5로 조정되어 있는 것을 확인할 수 있었다!
10차 부하 테스트
1. 변경점
- 설정값을 아래와 같이 조정했다.
| 설정값 | 변경 전 | 변경 후 |
| hikari maximum-pool-size | 100 | 80 |
| hikari minimum-idle | 기본값(설정하지 않으면 maximum-pool-size과 동일) | 5 |
| hikari idle-timeout | 기본값(8시간) | 10분 |
| Tomcat max-threads | 200 | 180 |
- 더미 데이터를 1차와 동일하게 총 131,000건으로 초기화했다.
2. k6 결과
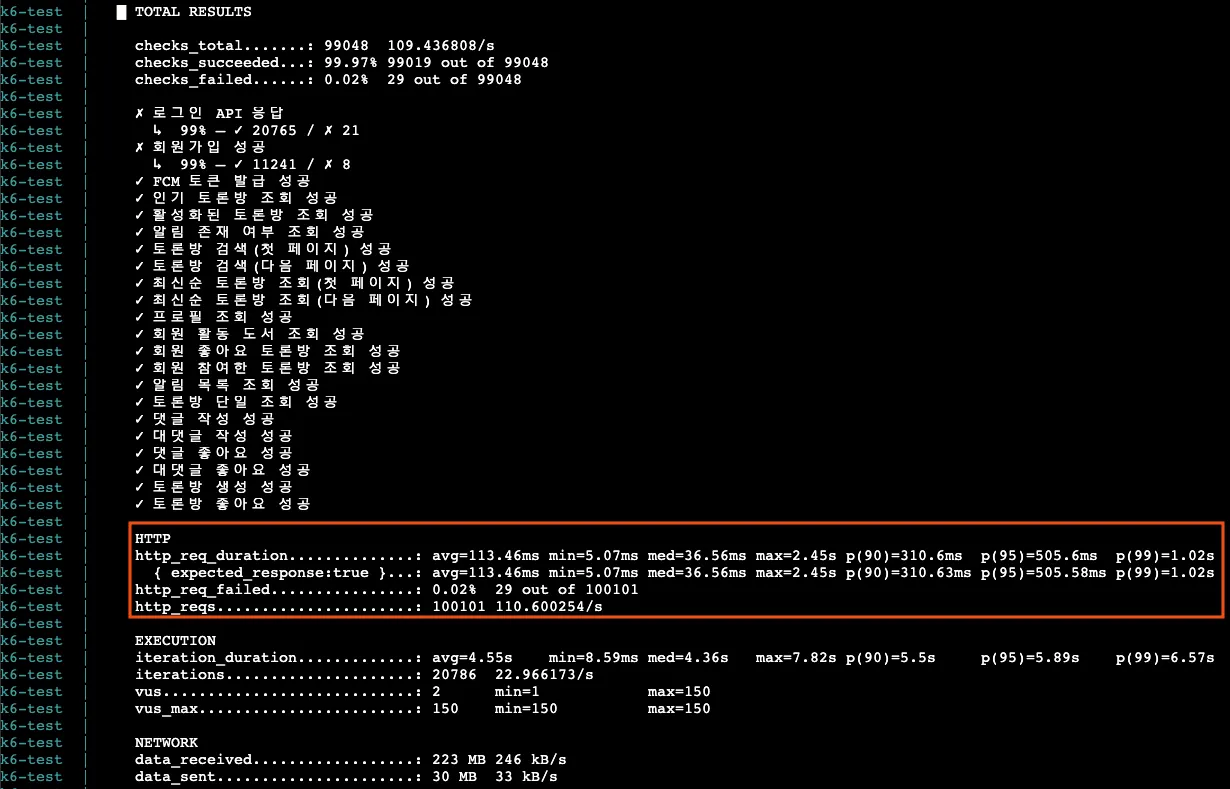
| 분류 | 5차 수치 | 현재 수치 |
| 총 요청 (http_reqs) | 63,207 | 100,101 |
| 실패요청 (http_req_failed) | 21 | 29 |
| 평균 응답시간 (Latency) | 572.89ms | 113.46ms |
| p95 응답시간 (Latency) | 2.1s | 505.6ms |
| p99 응답시간 (Latency) | 3.21s | 1.02s |
| 평균 TPS (http_reqs) | 69.734797/s | 110.600254/s |
가장 결과가 좋았던 5차 테스트에 비해서도 엄청난 개선을 확인할 수 있었다.
총 요청 수가 2배 가까이 늘어났고, p95/p99 응답시간도 목표치였던 1초, 2초보다 2배 이상 빨라졌다.
3. k6 prometheus monitoring

| 분류 | 5차 수치 | 현재 수치 |
| 총요청 (HTTP requests) | 55,603 | 89,955 |
| 실패요청 (HTTP request failures) | 21 | 29 |
| Peak RPS(TPS) | 145 req/s | 286 req/s |
서버 측에서 확인되는 값도 5차에 비해 2배 가까이 많아졌고, 그래프도 요청에 비례해서 안정적으로 확인된다.
Peak RPS도 286 까지 2배 이상 뛰었다!
4. Tomcat

| 분류 | 5차 수치 | 현재 수치 |
| Tomcat max threads | 200 | 180 |
| current busy threads | 최대 124 | 최대 126 |
| current threads | 최대 150 | 최대 150 |
지금까지 톰캣 스레드와 관련된 그래프는 굉장히 들쭉날쭉하기도 하고,
current threads가 지속적으로 늘어나 최대치에서 병목 현상을 보였었는데 이번 그래프에서는 증가-감소 패턴이 반복되는 모습을 확인할 수 있다.
DB에서 병목 없이 잘 처리되고 있다는 뜻으로 생각된다.
5. DBCP

| 분류 | 5차 수치 | 현재 수치 |
| Max Connections | 100 | 80 |
| Timeout Connection Count | 0 | 0 |
| Connections - Active | 88 | 75 |
| Connections - Pending | 35 | 최대 11 |
| Connection Acquire Time | 최대 0.06 | 최대 0.00603 |
드디어 안정적인 DBCP의 그래프를 볼 수 있게 되었다.
Active Connection은 max connections인 80 안에서 75까지 증가했고, pending은 11까지 존재했지만 acquire time이 거의 0에 수렴했으니, 커넥션 풀을 얻기 위해서 기다린 시간이 0.01초도 되지 않았다는 것!
6. CPU & I/O Time

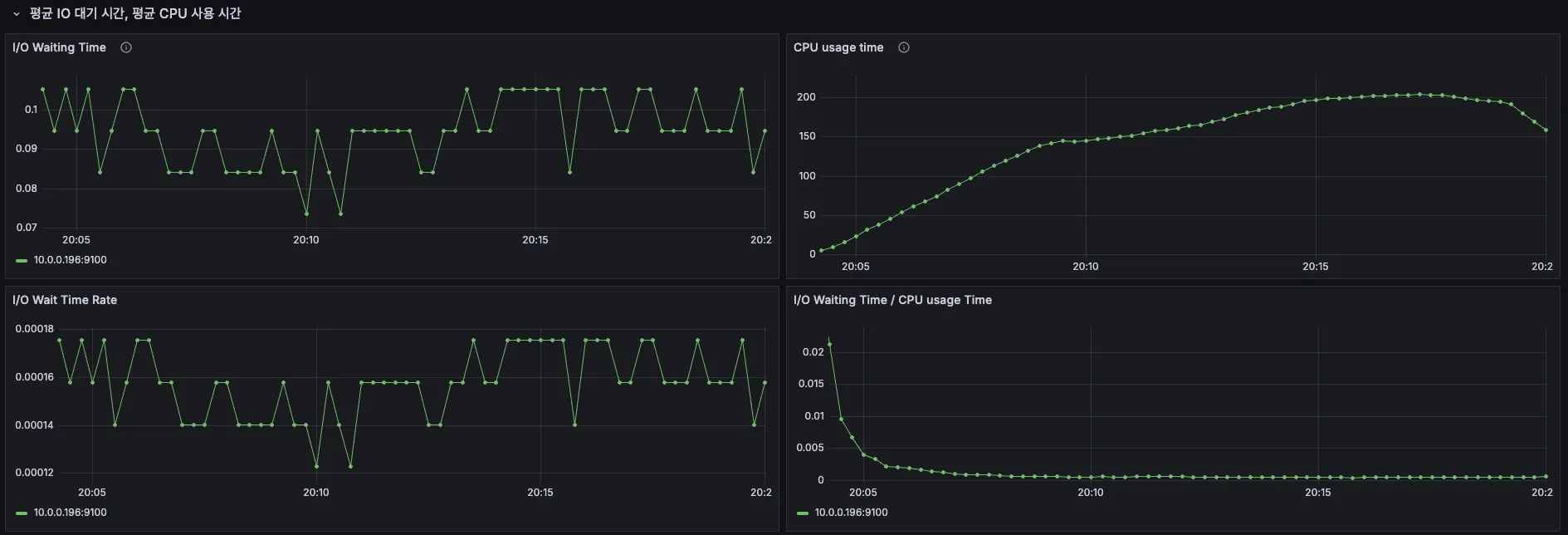

5차 때 Sys Load가 치솟았던 것과 다르게 이번에는 CPU 부하도, Sys Load도, Ram 사용량도, I/O Time도 안정적이었다.
RDS DB 서버의 CPU 사용률도 순간 최고 88%까지 찍긴 했으나, 이후 바로 수치가 낮아지는 모습을 보면 어느 정도 방어가 되고 있다고 생각된다.
7. API별 응답시간
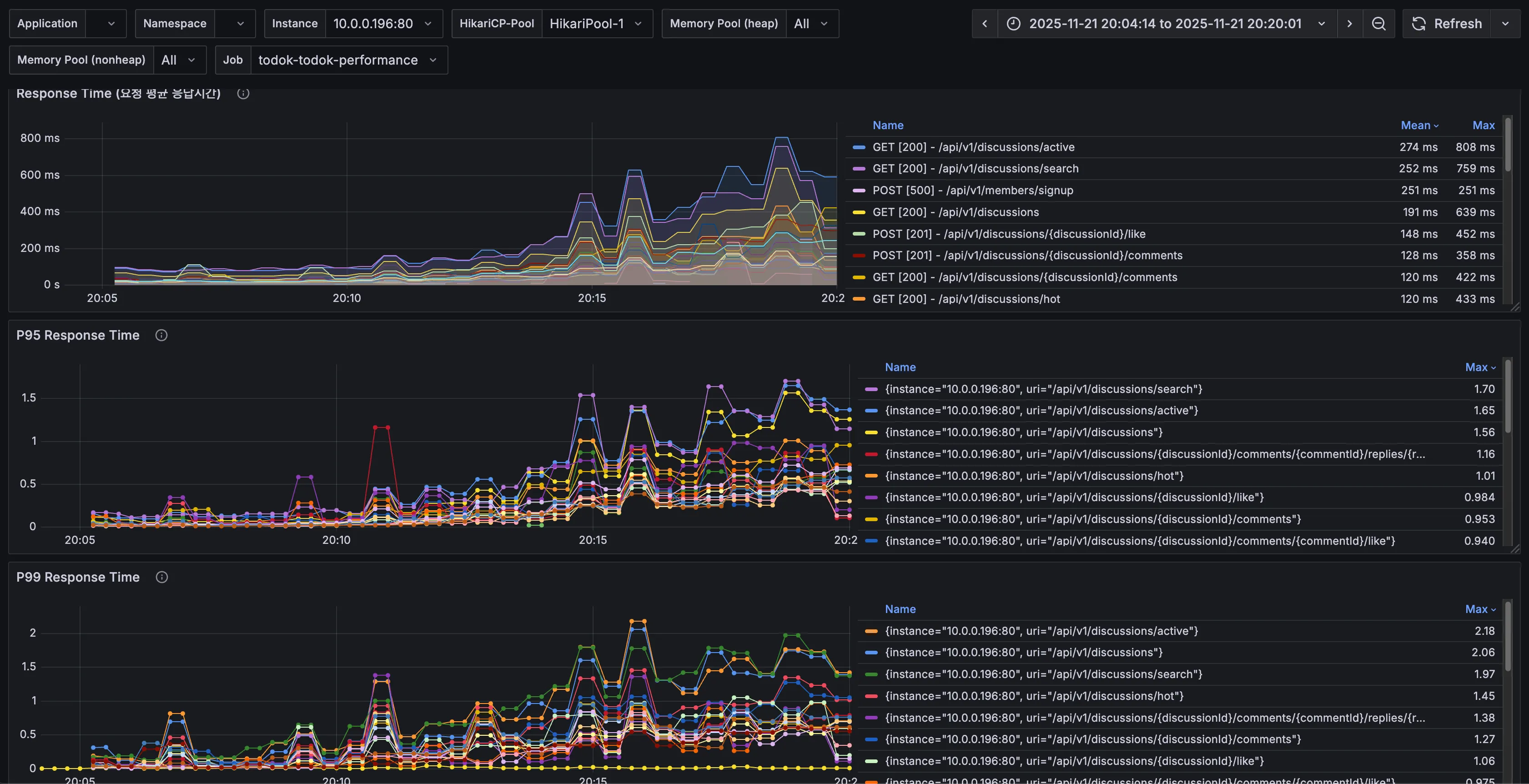
| API | 분류 | 5차 수치 | 현재 수치 | 개선 비율 |
| 토론방 검색(/api/v1/discussions/search) | Avg (Max) | 2.50s | 759ms | 69.64% |
| p95 (Max) | 4.16s | 1.7s | 59.13% | |
| p99 (Max) | 5.11s | 1.97s | 61.45% | |
| 인기 토론방 조회(/api/v1/discussions/hot) | Avg (Max) | 1.34s | 433ms | 67.76% |
| p95 (Max) | 3.81s | 1.01s | 73.50% | |
| p99 (Max) | 4.21s | 1.45s | 65.56% |
토론방 검색은 59~69%, 인기 토론방 조회는 65~73% 사이의 엄청난 성능 개선을 확인할 수 있었다.
수치 요약
- 총 요청, 평균/p95/p99 응답시간, 평균 TPS
| 분류 | 1차 | 5차 | 10차 | 1차 대비 10차 개선/증가 비율 |
| 총 요청 (http_reqs) | 25,693 | 63,207 | 100,101 | 289.6% 향상 |
| 실패요청 (http_req_failed) | 195 | 21 | 29 | 85.13% 감소 |
| 평균 응답시간 (Latency) | 2.88s | 572.89ms | 113.46ms | 96.06% 개선 |
| p95 응답시간 (Latency) | 6.45s | 2.1s | 505.6ms | 92.16% 개선 |
| p99 응답시간 (Latency) | 8.81s | 3.21s | 1.02s | 88.42% 개선 |
| 평균 TPS (http_reqs) | 28.001564/s | 69.734797/s | 110.600254/s | 295% 향상 |
- 느린 API 1 - 토론방 검색 (/api/v1/discussions/search)
| 분류 | 3차 | 5차 | 10차 | 3차 대비 10차 개선 비율 |
| Avg (Max) | 40.1s | 2.50s | 759ms | 98.11% 개선 |
| p95 (Max) | 30s | 4.16s | 1.7s | 94.33% 개선 |
| p99 (Max) | 30s | 5.11s | 1.97s | 93.43% 개선 |
- 느린 API 2 - 인기 토론방 조회 (/api/v1/discussions/hot)
| 분류 | 4차 | 5차 | 10차 | 3차 대비 10차 개선 비율 |
| Avg (Max) | 40.4s | 1.34s | 433ms | 98.93% 개선 |
| p95 (Max) | 30s | 3.81s | 1.01s | 96.63% 개선 |
| p99 (Max) | 30s | 4.21s | 1.45s | 95.17% 개선 |
배운점
10회의 부하 테스트를 통해 가장 크게 깨달은 점은 하드웨어 스펙을 확인/고려한 뒤 테스트를 해야한다는 점이다.
RDS를 사용할 땐 인스턴스의 메모리에 따라 적용된 max-connections 값을 확인하고 성능 튜닝을 진행해야 한다.
10차 테스트에서 설정한 hikari maximum-pool-size, Tomcat max-threads가 최적의 값이 아닐 수도 있다.
하지만 테스트를 하면서 하드웨어의 스펙을 고려하지 않고, 무작정 pool size를 늘렸다가 오히려 성능이 더 안 좋아지는 상황을 마주했다.
이를 깨닫고 하드웨어의 스펙을 고려하고 설정을 조정해 테스트를 하니 원하는 목표를 달성할 수 있었다.
또, 부하 테스트를 같은 조건에서 다른 결과를 내도록 진행하고 싶다면, 더미 데이터를 동일한 값으로 맞춘 후 진행하는 것이 신뢰도를 높일 수 있다.
몇 십, 몇 백만 단위의 대용량 데이터와 비교했을 때 내가 테스트한 규모는 아주 작을지라도 변경한 부분으로 어느 정도의 성능 향상이 있었는지 정확하게 확인하기 위해서라면 그 외의 값들은 동일해야 한다.
가장 크게 배운 점은 '사용자'로부터 시작한 테스트라는 것이다.
'사용자의 행동 흐름'을 예측하고, 이를 토대로 테스트에 맞춰 모킹하거나 로직을 수정하기도 하고, 쿼리를 튜닝하는 등 개선 작업을 거치니 테스트가 재미있었다.
앞으로도 어떻게 하면 성능을 개선할 수 있을지, 신뢰할 수 있고 안정성 있는 서버를 만들 수 있을지 힌트를 얻은 것 같다.
하고 싶은 것들이 많다!
추가로 개선 가능한 점
먼저, 매 테스트마다 확인됐던 리프레시 토큰 중복 로그 쪽을 확인해봐야 할 것 같다.
더 깊게 확인해봐야 정확히 알겠지만, 현재로서는 리프레시 토큰을 발급하고 DB에 저장하는 과정에서 유니크가 걸려 있지 않아 여러 스레드가 동시에 접근해서 발생하는 오류로 예상된다.
다음으로는 API별 응답 시간에서 응답시간이 느린 API들을 추가로 더 개선해 볼 수 있을 것 같다.
토론방 검색 API는 현재 MySQL의 전문 검색(full-text search) 기능을 사용하고 있는데, 데이터가 더 많아진다면 이 역시도 DB에 부하가 갈 것이다.
DB의 부하를 줄여주기 위해, 그리고 사용자 경험을 더욱 향상시키기 위해 Elasticsearch와 같은 전문 검색 엔진을 도입해볼 수도 있을 것 같다.
인기 토론방 API는 count column으로 반정규화를 시도했지만, 업데이트 도중 문제가 생긴다면 실제 데이터 집계 결과와 count column 간 불일치 문제가 생길 수 있다.
그렇기 때문에 주기적으로 원본 데이터와 집계 컬럼을 비교해서 동기화하는 배치 작업 스케줄링을 도입해볼 수 있을 것 같다.
이 API도 데이터가 더 많아진다면 count column만으로는 한계가 있을 것이다.
인기 토론방의 경우 오늘로부터 7일 간 댓글+대댓글+좋아요 수를 기준으로 정렬하는 것이기 때문에 데이터에 큰 변화가 없는 섹션이다.
그렇기 때문에 DB 부하를 줄이기 위해 Redis와 같은 외부 캐싱 처리를 도입해보는 것도 좋은 방법이라고 생각된다.
활성화된 토론방 API는 인기 토론방처럼 쿼리가 꽤 복잡하게 짜여져 있어서 쿼리 실행 계획을 확인해보고, 개선할 점을 찾아볼 수 있을 것 같다.
'study > 우아한테크코스' 카테고리의 다른 글
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 3 (부하 테스트 4~5차) (0) | 2025.12.01 |
|---|---|
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 2 (부하 테스트 1~3차) (0) | 2025.11.29 |
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 1 (시나리오 수정, 스모크 테스트) (0) | 2025.11.28 |
| 2025 WOOWACON(우아콘) 후기 (2) | 2025.10.29 |
| 우아한테크코스 7기 백엔드 레벨2 회고 (0) | 2025.06.29 |