4차 부하 테스트
1. 3차 테스트를 토대로 확인한 점
- AWS의 RDS 파라미터를 설정하면 Slow Query 로그를 확인할 수 있다.
3차 테스트 기간 동안 발생한 Slow Query를 확인해보니 아래 쿼리들이 확인되었다.
# 토론방 검색 API에 포함된 쿼리
select d1_0.id,count(distinct c1_0.id),count(distinct r1_0.id)
from discussion d1_0
left join comment c1_0 on (c1_0.deleted_at is NULL) and c1_0.discussion_id=d1_0.id
left join (reply r1_0 left join comment c2_0 on c2_0.id=r1_0.comment_id and (c2_0.deleted_at is NULL))
on (r1_0.deleted_at is NULL) and c2_0.discussion_id=d1_0.id
where (d1_0.deleted_at is NULL) and d1_0.id in (1,2,3,4,5,...약 1500개)
group by d1_0.id;
# 토론방 검색 API에 포함된 쿼리
select d1_0.id,count(dl1_0.id),case when sum(case when dl1_0.member_id=19020 then 1 else 0 end)>0 then 1 else 0 end
from discussion d1_0
left join discussion_like dl1_0 on (dl1_0.deleted_at is NULL) and dl1_0.discussion_id=d1_0.id
where (d1_0.deleted_at is NULL) and d1_0.id in (1,2,3,4,5,...약 1500개)
group by d1_0.id;
# 토론방 검색, 인기 토론방 API에 포함된 쿼리
select d1_0.id,count(distinct c1_0.id),count(distinct r1_0.id)
from discussion d1_0
left join comment c1_0 on (c1_0.deleted_at is NULL) and c1_0.discussion_id=d1_0.id and c1_0.created_at>='2025-11-13 09:00:00'
left join (reply r1_0 left join comment c2_0 on c2_0.id=r1_0.comment_id and (c2_0.deleted_at is NULL))
on (r1_0.deleted_at is NULL) and c2_0.discussion_id=d1_0.id and r1_0.created_at>='2025-11-13 09:00:00'
where (d1_0.deleted_at is NULL) and d1_0.id in (1,2,3,4,5,...약 1500개)
group by d1_0.id;
# 토론방 검색, 인기 토론방 API에 포함된 쿼리
select d1_0.id,count(dl1_0.id),case when sum(case when dl1_0.member_id=19020 then 1 else 0 end)>0 then 1 else 0 end
from discussion d1_0
left join discussion_like dl1_0 on (dl1_0.deleted_at is NULL) and dl1_0.discussion_id=d1_0.id and dl1_0.created_at>='2025-11-13 09:00:00'
where (d1_0.deleted_at is NULL) and d1_0.id
in (1,2,3,4,5,...약 1500개)
group by d1_0.id;- 지속적으로 request timeout 발생, 응답 시간이 가장 길었던 '토론방 검색 API(/api/v1/discussions/search)'의 Service, Repository 코드는 아래와 같았다.
// 토론방 검색 시작 - 키워드 검증 및 멤버 조회
public List<DiscussionResponse> getDiscussionsByKeyword(
final Long memberId,
final String keyword
) {
validateKeywordNotBlank(keyword);
final Member member = findMember(memberId);
return getDiscussionsByKeyword(keyword, member);
}
// 키워드로 토론방 검색 및 응답 생성
private List<DiscussionResponse> getDiscussionsByKeyword(
final String keyword,
final Member member
) {
final String keywordWithPrefix = String.format("+%s*", keyword);
final List<Long> discussionIds = discussionRepository.searchIdsByKeyword(keywordWithPrefix);
return getDiscussionsResponses(discussionIds, member);
}
// 키워드로 토론방 검색 쿼리 (Full text index 적용)
@Query(value = """
SELECT d.id
FROM discussion d
WHERE MATCH(d.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
UNION
SELECT d.id
FROM discussion d
JOIN book b ON d.book_id = b.id
WHERE MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
AND b.deleted_at IS NULL
""", nativeQuery = true)
List<Long> searchIdsByKeyword(@Param("keyword") final String keyword);
// 응답 생성
private List<DiscussionResponse> getDiscussionsResponses(
final List<Long> discussionIds,
final Member member
) {
if (discussionIds.isEmpty()) {
return List.of();
}
final List<DiscussionLikeSummaryDto> likeSummaries = discussionLikeRepository.findLikeSummaryByDiscussionIds(
member, discussionIds);
final List<DiscussionCommentCountDto> commentCounts = commentRepository.findCommentCountsByDiscussionIds(
discussionIds);
final Map<Long, LikeCountAndIsLikedByMeDto> likesByDiscussionId = mapLikeSummariesByDiscussionId(likeSummaries);
final Map<Long, Integer> commentsByDiscussionId = mapTotalCommentCountsByDiscussionId(commentCounts);
return makeResponsesFrom(discussionIds, likesByDiscussionId, commentsByDiscussionId);
}
// 좋아요 갯수, 내가 좋아요했는지 여부 카운트 쿼리 => 찾았다 범인!
@Query("""
SELECT new todoktodok.backend.discussion.application.service.query.DiscussionLikeSummaryDto(
d.id,
COUNT(dl),
CASE WHEN SUM(CASE WHEN dl.member = :member THEN 1 ELSE 0 END) > 0
THEN true
ELSE false END
)
FROM Discussion d
LEFT JOIN DiscussionLike dl ON dl.discussion = d
WHERE d.id IN :discussionIds
GROUP BY d.id
""")
List<DiscussionLikeSummaryDto> findLikeSummaryByDiscussionIds(
@Param("member") final Member member,
@Param("discussionIds") final List<Long> discussionIds
);
// 댓글, 대댓글 카운트 쿼리 => 찾았다 범인!
@Query("""
SELECT new todoktodok.backend.discussion.application.service.query.DiscussionCommentCountDto(
d.id,
COUNT(DISTINCT c.id),
COUNT(DISTINCT r.id)
)
FROM Discussion d
LEFT JOIN Comment c ON c.discussion = d
LEFT JOIN Reply r ON r.comment = c
WHERE d.id IN :discussionIds
GROUP BY d.id
""")
List<DiscussionCommentCountDto> findCommentCountsByDiscussionIds(@Param("discussionIds") final List<Long> discussionIds);
// 좋아요 갯수, 내가 좋아요했는지 여부 DTO에서 토론방 ID 추출
private Map<Long, LikeCountAndIsLikedByMeDto> mapLikeSummariesByDiscussionId(
final List<DiscussionLikeSummaryDto> likeCounts) {
return likeCounts.stream()
.collect(Collectors.toMap(
DiscussionLikeSummaryDto::discussionId,
discussionLikeSummaryDto ->
new LikeCountAndIsLikedByMeDto(
discussionLikeSummaryDto.likeCount(),
discussionLikeSummaryDto.isLikedByMe()
)
));
}
// 댓글, 대댓글 DTO에서 토론방 ID 추출
private Map<Long, Integer> mapTotalCommentCountsByDiscussionId(
final List<DiscussionCommentCountDto> commentCounts) {
return commentCounts.stream()
.collect(Collectors.toMap(
DiscussionCommentCountDto::discussionId,
dto -> dto.commentCount() + dto.replyCount()
));
}
// 추출한 ID들로 생성
private List<DiscussionResponse> makeResponsesFrom(
final List<Long> discussionIds,
final Map<Long, LikeCountAndIsLikedByMeDto> likeSummaryByDiscussionId,
final Map<Long, Integer> commentCountsByDiscussionId
) {
final Map<Long, Discussion> discussions = discussionRepository.findDiscussionsInIds(discussionIds).stream()
.collect(Collectors.toMap(Discussion::getId, discussion -> discussion));
return discussionIds.stream()
.map(discussionId -> {
final Discussion discussion = discussions.get(discussionId);
final int likeCount = likeSummaryByDiscussionId.get(discussionId).likeCount();
final int commentCount = commentCountsByDiscussionId.getOrDefault(discussionId, 0);
final boolean isLikedByMe = likeSummaryByDiscussionId.get(discussionId).isLikedByMe();
return new DiscussionResponse(discussion, likeCount, commentCount, isLikedByMe);
})
.toList();
}
위 코드에서 댓글, 대댓글 카운트 쿼리(findCommentCountsByDiscussionIds)를 보면 키워드를 통해 검색한 discussionIds의 갯수(쿼리에서 where절 in 부분)가 AWS Slow Query를 토대로 약 1,500개 정도이다.
약 1,500개의 discussionIds를 각 26,000건의 comment 테이블, reply 테이블과 다중조인하게 되면 1개의 discussionId 당 최대 약 25배(토론방:댓글:대댓글==1:5:5 비율이므로 5*5)로 증가할 것이다.
하나의 쿼리에 1:N 조인도 아니고, 댓글, 대댓글까지 1:N:M의 조인을 해서 데이터를 증가시킨 뒤, 다시 GROUP BY, COUNT(DISTINCT)로 결과를 합치고 있다.
2. 변경점
- 시나리오 스크립트: 토론방 조회 API를 호출하는 부분에서 페이지네이션을 적용할 수 있도록 수정해주었다.
- 비즈니스 로직: 토론방 검색 로직을 수정했다. 고려한 해결책들은 아래 표와 같았다.
| 해결책 | 1. 반정규화로 집계 쿼리 개선 | 2. 서브쿼리 최적화로 집계 쿼리 개선 | 3. Cursor 기반 페이징 처리 |
| 장점 | - 집계 비용 제거 - 비즈니스 로직 단순화 - 다른 로직에서도 활용 가능 |
- 데이터 폭증 원천 차단 - 쿼리 로직 단순화 |
- 일정한 성능 보장 - 구현 난이도 쉬움 - 프로젝트의 다른 조회 API 구현과 통일성 |
| 단점 | - 댓글/대댓글/좋아요 생성 시 컬럼 업데이트로 부하 가능성 - 테이블 수정, 코드 수정 증가 - 데이터 정합성 문제 생길 수 있어 동시성 처리 필요 |
- 대량 조회 시 성능 저하 - 쿼리 가독성 저하 |
- 정렬 기준이 복잡하면 쿼리 복잡성 증가 - API 스펙 변경 |
반정규화나 서브쿼리로 집계 쿼리를 개선하는 것도 좋은 방법이라고 생각했지만, 현재 문제점은 '토론방 검색 API가 느리다'는 것이었다.
토론방 검색은 사용자가 검색어를 입력하고, 검색된 결과를 받아보는 상황인데 전체 검색 결과를 반환하고 있었다.
또, 검색 결과는 최신순으로 반환하고 있었기 때문에 당장 집계 쿼리 자체를 바꾸기보다 해당 쿼리로 넘겨주는 전체 검색 결과를 제한하는 것이 좋겠다고 판단했다.
프로젝트의 다른 조회 API에서도 Cursor 기반 페이지네이션을 적용하고 있었으므로, 통일성 있게 Cursor 기반 페이지네이션을 적용해 스캔 범위를 선행 제한했고, 쿼리에서는 연산 대상을 수천 건에서 수십 건으로 최소화해 필요한 데이터만 조인하여 계산할 수 있었다.
- 수정 코드
// 토론방 검색 컨트롤러 - 페이지네이션 적용
@Auth(value = Role.USER)
@GetMapping("/search")
public ResponseEntity<LatestDiscussionPageResponse> getDiscussionsByKeyword(
@LoginMember final Long memberId,
@RequestParam final String keyword,
@RequestParam final int size,
@RequestParam(required = false) final String cursor
) {
return ResponseEntity.status(HttpStatus.OK)
.body(discussionQueryService.getDiscussionsByKeywordWithPagination(memberId, keyword, size, cursor));
}
// 토론방 검색 서비스
public LatestDiscussionPageResponse getDiscussionsByKeywordWithPagination(
final Long memberId,
final String keyword,
final int size,
final String cursor
) {
validateKeywordNotBlank(keyword);
validatePageSize(size);
final Member member = findMember(memberId);
final String keywordWithPrefix = String.format("+%s*", keyword);
// 전체 개수 조회
final long totalCount = discussionRepository.countSearchResultsByKeyword(keywordWithPrefix);
// 페이지네이션된 결과 조회
final Slice<Long> discussionIdsSlice = sliceDiscussionsByKeyword(keyword, cursor, size);
return createPageResponseWithTotalCount(discussionIdsSlice, member, totalCount);
}
// 페이지네이션된 결과 조회
private Slice<Long> sliceDiscussionsByKeyword(
final String keyword,
final String cursor,
final int size
) {
final String keywordWithPrefix = String.format("+%s*", keyword);
final Pageable pageable = PageRequest.of(0, size, Direction.DESC, "id");
final Long cursorId = (cursor == null || cursor.isBlank()) ? null : decodeCursor(cursor);
return discussionRepository.searchIdsByKeywordWithCursor(keywordWithPrefix, cursorId, pageable);
}
// 반환 응답 생성
private LatestDiscussionPageResponse createPageResponseWithTotalCount(
final Slice<Long> discussionIdsSlice,
final Member member,
final long totalCount
) {
final List<Long> discussionIds = discussionIdsSlice.getContent();
final boolean hasNextPage = discussionIdsSlice.hasNext();
final String nextCursor = findNextCursor(hasNextPage, discussionIds);
return new LatestDiscussionPageResponse(
getDiscussionsResponses(discussionIds, member),
new PageInfo(hasNextPage, nextCursor, totalCount)
);
}
// Full Text Index 활용 검색 시 페이지네이션 적용
@Query(value = """
SELECT * FROM (
SELECT d.id
FROM discussion d
WHERE MATCH(d.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
UNION
SELECT d.id
FROM discussion d
JOIN book b ON d.book_id = b.id
WHERE MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
AND b.deleted_at IS NULL
) AS search_results
WHERE :cursorId IS NULL OR id < :cursorId
ORDER BY id DESC
""", nativeQuery = true)
Slice<Long> searchIdsByKeywordWithCursor(
@Param("keyword") final String keyword,
@Param("cursorId") final Long cursorId,
final Pageable pageable
);
// 응답 반환 시 검색 결과 전체 개수 조회를 위한 쿼리
@Query(value = """
SELECT COUNT(DISTINCT id) FROM (
SELECT d.id
FROM discussion d
WHERE MATCH(d.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
UNION
SELECT d.id
FROM discussion d
JOIN book b ON d.book_id = b.id
WHERE MATCH(b.title) AGAINST(:keyword IN BOOLEAN MODE)
AND d.deleted_at IS NULL
AND b.deleted_at IS NULL
) AS search_results
""", nativeQuery = true)
long countSearchResultsByKeyword(@Param("keyword") final String keyword);
3. k6 결과

| 분류 | 직전 수치 | 현재 수치 |
| 총 요청 (http_reqs) | 22,395 | 20,483 |
| 실패요청 (http_req_failed) | 95 | 4 |
| 평균 응답시간 (Latency) | 3.4s | 3.78s |
| p95 응답시간 (Latency) | 19.71s | 19.73s |
| p99 응답시간 (Latency) | 27.28s | 38.64s |
| 평균 TPS (http_reqs) | 24.265373/s | 22.045908/s |
직전에 비해 전체적인 수치는 안 좋아졌으나, request timeout이 뜨던 토론방 검색 API의 실패 횟수가 사라졌다.
전체적인 수치가 좋아지지 않은 점은 남은 Slow Query를 개선해보면 되지 않을까 생각된다.
4. k6 prometheus monitoring
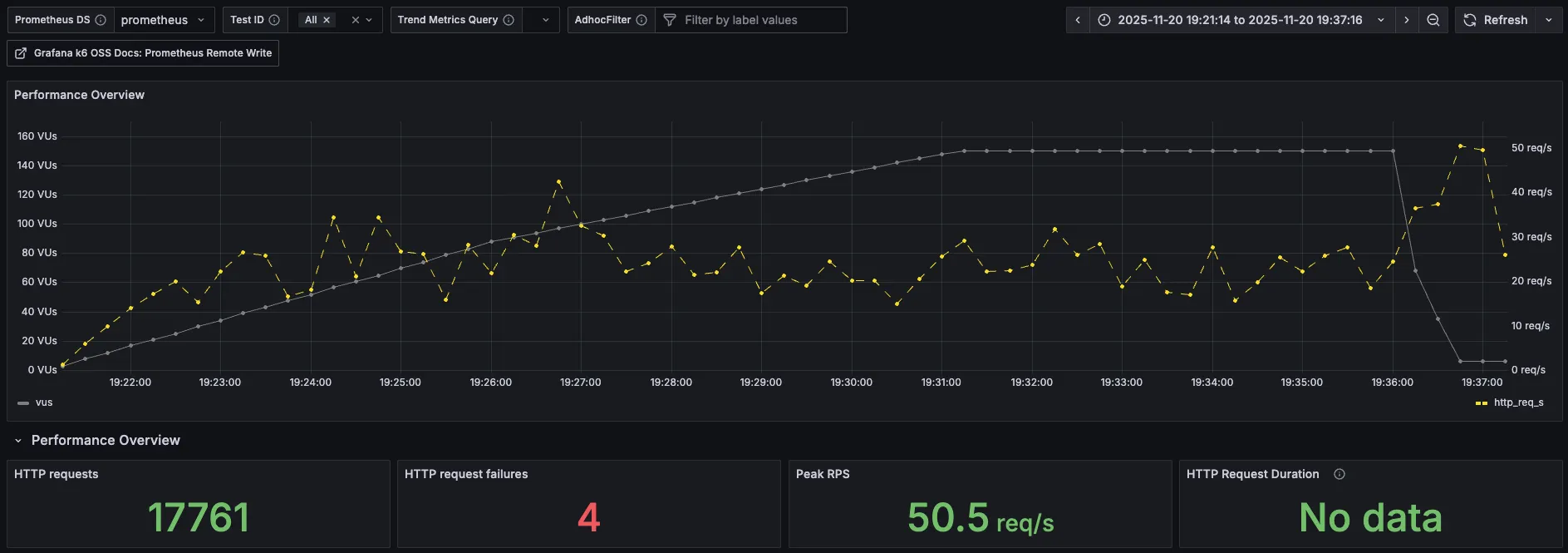
| 분류 | 직전 수치 | 현재 수치 |
| 총요청 (HTTP requests) | 19,594 | 17,761 |
| 실패요청 (HTTP request failures) | 93 | 4 |
| Peak RPS(TPS) | 205 req/s | 50.5 req/s |
3차 때엔 그래프가 한 번 크게 치솟았었는데, 이번에는 오히려 더 안정적인 그래프가 나왔다.
요청 실패가 많이 줄어든 것을 보면 오래 기다렸을 뿐 응답을 하긴 했다고 예측된다.
5. Tomcat
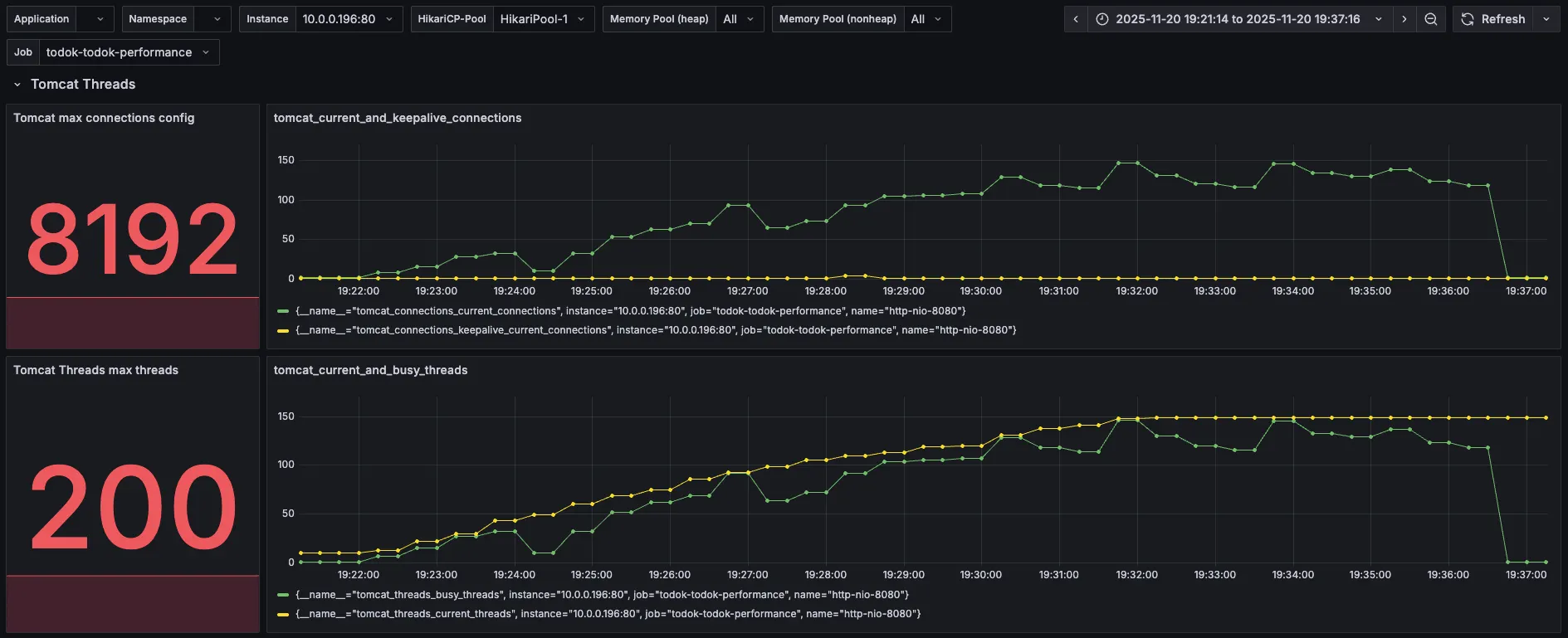
| 분류 | 직전 수치 | 현재 수치 |
| Tomcat max threads | 200 | 200 |
| current busy threads | 150 살짝 초과 | 최대 150 근접 |
| current threads | 150 살짝 초과 | 최대 150 근접 |
2차 때와 비슷한 모습이다.
6. DBCP

| 분류 | 직전 수치 | 현재 수치 |
| Max Connections | 100 | 100 |
| Timeout Connection Count | 0 | 0 |
| Connections - Active | 88 | 88 |
| Connections - Pending | 83 | 60 |
| Connection Acquire Time | 최대 1 | 최대 0.85 |
Pending의 값이 직전보다 살짝 줄었고, Acquire Time도 줄었지만 여전히 병목은 존재한다.
7. CPU & I/O Time

이번에도 역시 특이한 점이 없다!
8. API별 응답시간
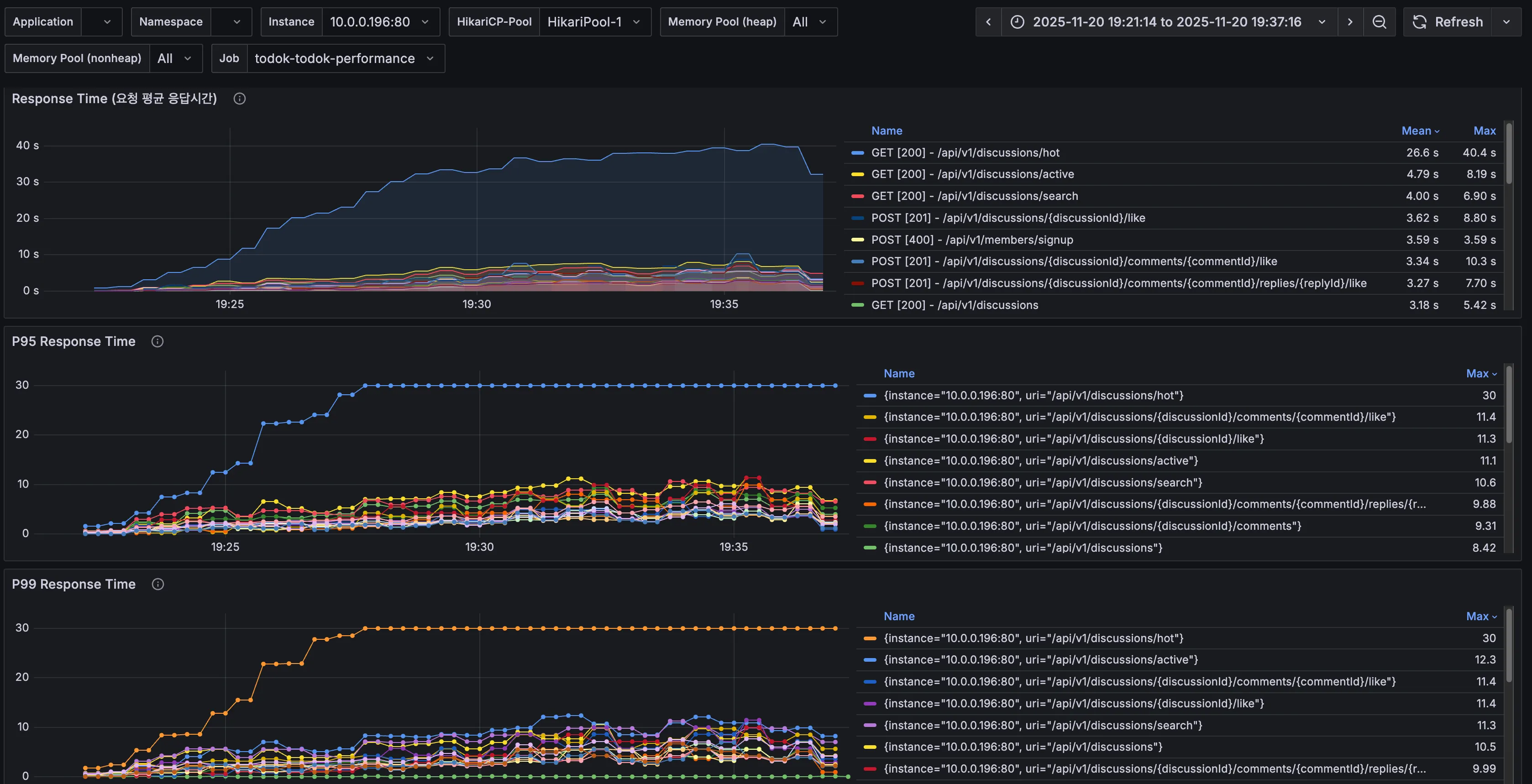
| API | 분류 | 직전 수치 | 현재 수치 | 개선 비율 |
| 토론방 검색(/api/v1/discussions/search) | Avg (Max) | 40.1s | 6.90s | 82.8% |
| p95 (Max) | 30s | 10.6s | 64.7% | |
| p99 (Max) | 30s | 11.3s | 62.3% |
페이지네이션 처리만 해주었는데도 토론방 검색 API의 평균, p95, p99 응답 시간이 대폭 개선되었다.
하지만 여전히 좋은 수치는 아니며, 다음으로 인기 토론방 API가 많이 지연되고 있음을 확인할 수 있다.
9. 결론 및 해결책
토론방 검색 API만 보았을 땐 응답시간이 평균 82.8%, p95 64.7%, p99 62.3%로 많이 개선되었다.
하지만 전체적인 처리량, 응답시간은 3차보다 더 악화되었다.
Slow Query에서 확인되었던 또 다른 쿼리(토론방 검색, 인기 토론방 조회에 함께 존재)를 튜닝해준다면 성능 향상에 더 효과적이지 않을까 예상해본다.
5차 부하 테스트
1. 4차 테스트를 토대로 확인한 점
- 4차에서 토론방 검색 다음으로 느린 API로 확인되었던 '인기 토론방 조회 API(/api/v1/discussions/hot)'의 Service, Repository 코드는 아래와 같았다.
// 인기 토론방 조회 시작
public List<DiscussionResponse> getHotDiscussions(
final Long memberId,
final int period,
final int count
) {
validateDiscussionPeriod(period);
validateHotDiscussionCount(count);
final Member member = findMember(memberId);
final LocalDateTime sinceDate = LocalDate.now().minusDays(period).atStartOfDay();
final List<Long> discussionIds = discussionRepository.findAllIds();
if (discussionIds.isEmpty()) {
return Collections.emptyList();
}
final List<DiscussionLikeSummaryDto> likeSinceCounts = discussionLikeRepository.findLikeSummariesByDiscussionIdsSinceDate(
member, discussionIds, sinceDate);
final List<DiscussionCommentCountDto> commentSinceCounts = commentRepository.findCommentCountsByDiscussionIdsSinceDate(
discussionIds, sinceDate);
final Map<Long, LikeCountAndIsLikedByMeDto> likesByDiscussionId = mapLikeSummariesByDiscussionId(
likeSinceCounts);
final Map<Long, Integer> commentsByDiscussionId = mapTotalCommentCountsByDiscussionId(commentSinceCounts);
final List<Long> hotDiscussionIds = findHotDiscussions(count, likesByDiscussionId, commentsByDiscussionId,
discussionIds);
return getDiscussionsResponses(hotDiscussionIds, member);
}
// 전체 토론방 id 조회 => 이것도 토론방 갯수가 커지면 부하의 원인이 될 수 있음
@Query("""
SELECT d.id
FROM Discussion d
""")
List<Long> findAllIds();
// 최근 7일 간 좋아요 갯수, 내가 좋아요했는지 여부 카운트 쿼리 => 찾았다 범인!
@Query("""
SELECT new todoktodok.backend.discussion.application.service.query.DiscussionLikeSummaryDto(
d.id,
COUNT(dl),
CASE WHEN SUM(CASE WHEN dl.member = :member THEN 1 ELSE 0 END) > 0
THEN true
ELSE false END
)
FROM Discussion d
LEFT JOIN DiscussionLike dl ON dl.discussion = d AND dl.createdAt >= :sinceDate
WHERE d.id IN :discussionIds
GROUP BY d.id
""")
List<DiscussionLikeSummaryDto> findLikeSummariesByDiscussionIdsSinceDate(
@Param("member") final Member member,
@Param("discussionIds") final List<Long> discussionIds,
@Param("sinceDate") final LocalDateTime sinceDate
);
// 최근 7일 간 댓글, 대댓글 카운트 쿼리 => 찾았다 범인!
@Query("""
SELECT new todoktodok.backend.discussion.application.service.query.DiscussionCommentCountDto(
d.id,
COUNT(DISTINCT c.id),
COUNT(DISTINCT r.id)
)
FROM Discussion d
LEFT JOIN Comment c ON c.discussion = d AND c.createdAt >= :sinceDate
LEFT JOIN Reply r ON r.comment.discussion = d AND r.createdAt >= :sinceDate
WHERE d.id IN :discussionIds
GROUP BY d.id
""")
List<DiscussionCommentCountDto> findCommentCountsByDiscussionIdsSinceDate(
@Param("discussionIds") final List<Long> discussionIds,
@Param("sinceDate") final LocalDateTime sinceDate
);
// 좋아요 갯수, 내가 좋아요했는지 여부 DTO에서 토론방 ID 추출
private Map<Long, LikeCountAndIsLikedByMeDto> mapLikeSummariesByDiscussionId(
final List<DiscussionLikeSummaryDto> likeCounts) {
return likeCounts.stream()
.collect(Collectors.toMap(
DiscussionLikeSummaryDto::discussionId,
discussionLikeSummaryDto ->
new LikeCountAndIsLikedByMeDto(
discussionLikeSummaryDto.likeCount(),
discussionLikeSummaryDto.isLikedByMe()
)
));
}
// 댓글, 대댓글 DTO에서 토론방 ID 추출
private Map<Long, Integer> mapTotalCommentCountsByDiscussionId(
final List<DiscussionCommentCountDto> commentCounts) {
return commentCounts.stream()
.collect(Collectors.toMap(
DiscussionCommentCountDto::discussionId,
dto -> dto.commentCount() + dto.replyCount()
));
}
// 인기 토론방 id 추출 (좋아요+댓글+대댓글 합이 많은 순서대로 TOP count(5)개)
private static List<Long> findHotDiscussions(
final int count,
final Map<Long, LikeCountAndIsLikedByMeDto> likesByDiscussionId,
final Map<Long, Integer> commentsByDiscussionId,
final List<Long> discussionIds
) {
final ToIntFunction<Long> totalCountByDiscussion =
discussionId ->
likesByDiscussionId.get(discussionId).likeCount()
+ commentsByDiscussionId.getOrDefault(discussionId, 0);
return discussionIds.stream()
.sorted(Comparator
.comparingInt(totalCountByDiscussion)
.reversed()
.thenComparing(discussionId -> discussionId, Comparator.reverseOrder())
)
.limit(count)
.toList();
}
// hot discussionIds로 응답 생성 => 쿼리가 중복도 있는 것 같고 많아짐..!
private List<DiscussionResponse> getDiscussionsResponses(
final List<Long> discussionIds,
final Member member
) {
if (discussionIds.isEmpty()) {
return List.of();
}
final List<DiscussionLikeSummaryDto> likeSummaries = discussionLikeRepository.findLikeSummaryByDiscussionIds(
member, discussionIds);
final List<DiscussionCommentCountDto> commentCounts = commentRepository.findCommentCountsByDiscussionIds(
discussionIds);
final Map<Long, LikeCountAndIsLikedByMeDto> likesByDiscussionId = mapLikeSummariesByDiscussionId(likeSummaries);
final Map<Long, Integer> commentsByDiscussionId = mapTotalCommentCountsByDiscussionId(commentCounts);
return makeResponsesFrom(discussionIds, likesByDiscussionId, commentsByDiscussionId);
}
토론방 검색 API에서 Slow Query로 확인됐던 쿼리와 비슷하긴 하지만,
인기 토론방은 7일 이내 댓글+대댓글+좋아요 카운트를 계산해야 하기 때문에 집계 쿼리에 sinceDate 파라미터가 존재한다는 차이가 있다.
2. 변경점
- 비즈니스 로직: 인기 토론방 로직을 수정했다. 고려한 해결책들은 아래 표와 같았다.
| 해결책 | 1. count column 추가 | 2. 통계 테이블 추가 | 3. Redis 등 외부 캐시 |
| 장점 | - 집계 비용 제거 - 비즈니스 로직 단순화 - 토론방 검색에서도 활용 가능 |
- 매우 빠른 조회 - DB 서버 부하 분산 |
- 응답 속도 극대화 - DB 부하 최소화 |
| 단점 | - 댓글/대댓글/좋아요 생성 시 컬럼 업데이트로 부하 가능성 - 테이블 수정, 코드 수정 증가 - 데이터 정합성 문제 생길 수 있어 동시성 처리 필요 |
- 대량 조회 시 성능 저하 - 쿼리 가독성 저하 |
- Redis 서버 운영 및 관리 부담 추가로 복잡성 증가 - 데이터의 실시간성 저하 |
현재 1만 정도 사용자를 예상한 상황이었기 때문에 Redis 와 같은 외부 캐시는 러닝 커브가 있고 복잡성이 증가한다는 단점이 크게 다가왔다.
이미 discussion 테이블에 조회수 카운트를 위한 view_count column이 존재하고 있었기 때문에 통계 테이블을 별도로 분리하는 것보다 댓글+대댓글을 위한 comment_count, 좋아요를 위한 like_count 컬럼만 추가해주는 것이 효율적이라고 판단했다.
다만, 댓글/대댓글/좋아요 생성 시 컬럼 업데이트가 필요하기 때문에 데이터의 정합성 문제가 생길 수 있었다.
이 점은 조회수 구현을 통해 인지하고 있던 부분이었으므로 동일하게 트랜잭션 범위를 최소화하여 원자적 갱신으로 정합성을 함께 보장했다.
추가로, 쿼리에서 where절의 created_at 컬럼에 인덱스를 추가해주면 조회 성능이 더 향상될 것이라고 생각돼 함께 추가해주었다.
- 수정 코드 1 (DDL)
-- 토론방 테이블에 카운트 컬럼 추가
ALTER TABLE discussion
ADD COLUMN like_count INT NOT NULL DEFAULT 0,
ADD COLUMN comment_count INT NOT NULL DEFAULT 0;
-- 기존 데이터의 좋아요 카운트 초기화
UPDATE discussion d
SET like_count = (
SELECT COUNT(*)
FROM discussion_like dl
WHERE dl.discussion_id = d.id
AND dl.deleted_at IS NULL
);
-- 기존 데이터의 댓글 카운트 초기화 (댓글 + 대댓글)
UPDATE discussion d
SET comment_count = (
SELECT COALESCE(
(SELECT COUNT(*)
FROM comment c
WHERE c.discussion_id = d.id
AND c.deleted_at IS NULL),
0
) + COALESCE(
(SELECT COUNT(*)
FROM reply r
JOIN comment c ON r.comment_id = c.id
WHERE c.discussion_id = d.id
AND r.deleted_at IS NULL
AND c.deleted_at IS NULL),
0
)
);
-- 인기 토론방 조회 성능 개선을 위한 인덱스 추가
-- WHERE created_at >= :sinceDate 필터링 최적화
CREATE INDEX idx_discussion_created_at ON discussion(created_at DESC);
- 수정 코드 2
// 인기 토론방 조회 시작
public List<DiscussionResponse> getHotDiscussions(
final Long memberId,
final int period,
final int count
) {
validateDiscussionPeriod(period);
validateHotDiscussionCount(count);
final Member member = findMember(memberId);
final LocalDateTime sinceDate = LocalDate.now().minusDays(period).atStartOfDay();
final Pageable pageable = PageRequest.of(0, count);
// discussion 테이블의 likeCount + commentCount 컬럼으로 정렬
final List<Long> hotDiscussionIds = discussionRepository.findHotDiscussionIdsSinceDate(sinceDate, pageable);
return getDiscussionsResponses(hotDiscussionIds, member);
}
// 댓글 카운트 컬럼 + 좋아요 카운트 컬럼으로 정렬, 7일 이내만 필터링한 인기토론방 검색 쿼리
@Query("""
SELECT d.id
FROM Discussion d
WHERE d.createdAt >= :sinceDate
ORDER BY (d.likeCount + d.commentCount) DESC, d.id DESC
""")
List<Long> findHotDiscussionIdsSinceDate(
@Param("sinceDate") final LocalDateTime sinceDate,
final Pageable pageable
);
// hot discussionIds로 응답 생성
private List<DiscussionResponse> getDiscussionsResponses(
final List<Long> discussionIds,
final Member member
) {
if (discussionIds.isEmpty()) {
return List.of();
}
// isLikedByMe 정보만 조회 (likeCount와 commentCount는 Discussion 엔티티에서 직접 가져옴)
final List<Long> likedDiscussionIds = discussionLikeRepository.findLikedDiscussionIdsByMemberAndDiscussionIds(
member, discussionIds);
final Map<Long, Boolean> isLikedByMeMap = discussionIds.stream()
.collect(Collectors.toMap(id -> id, likedDiscussionIds::contains));
return makeResponsesFrom(discussionIds, isLikedByMeMap);
}
// 반환 응답 생성
private List<DiscussionResponse> makeResponsesFrom(
final List<Long> discussionIds,
final Map<Long, Boolean> isLikedByMeMap
) {
final Map<Long, Discussion> discussions = discussionRepository.findDiscussionsInIds(discussionIds).stream()
.collect(Collectors.toMap(Discussion::getId, discussion -> discussion));
return discussionIds.stream()
.map(discussionId -> {
final Discussion discussion = discussions.get(discussionId);
// Discussion 엔티티의 카운트 컬럼 직접 사용
final int likeCount = discussion.getLikeCount();
final int commentCount = discussion.getCommentCount();
final boolean isLikedByMe = isLikedByMeMap.getOrDefault(discussionId, false);
return new DiscussionResponse(discussion, likeCount, commentCount, isLikedByMe);
})
.toList();
}
3. k6 결과

| 분류 | 직전 수치 | 현재 수치 |
| 총 요청 (http_reqs) | 20,483 | 63,207 |
| 실패요청 (http_req_failed) | 4 | 21 |
| 평균 응답시간 (Latency) | 3.78s | 572.89ms |
| p95 응답시간 (Latency) | 19.73s | 2.1s |
| p99 응답시간 (Latency) | 38.64s | 3.21s |
| 평균 TPS (http_reqs) | 22.045908/s | 69.734797/s |
인증과 관련된 실패 요청이 조금 있긴 했지만, Slow query와 로직을 개선하고 나니 총 요청도 많이 증가하고, 응답시간이 엄청 낮아졌다.
평균 TPS도 3배 정도 높아졌다.
하지만 여전히 p95, p99 응답시간의 값이 목표치인 1초, 2초에는 미치지 못했다.
4. k6 prometheus monitoring

| 분류 | 직전 수치 | 현재 수치 |
| 총요청 (HTTP requests) | 17,761 | 55,603 |
| 실패요청 (HTTP request failures) | 4 | 21 |
| Peak RPS(TPS) | 50.5 req/s | 145 req/s |
prometheus에서 찍힌 총 요청도 훠~얼씬 많아졌고 그래프도 VU가 증가하는 만큼 요청도 증가하는 모양새로 안정화되었다.
Peak RPS도 145까지 상승했다.
5. Tomcat
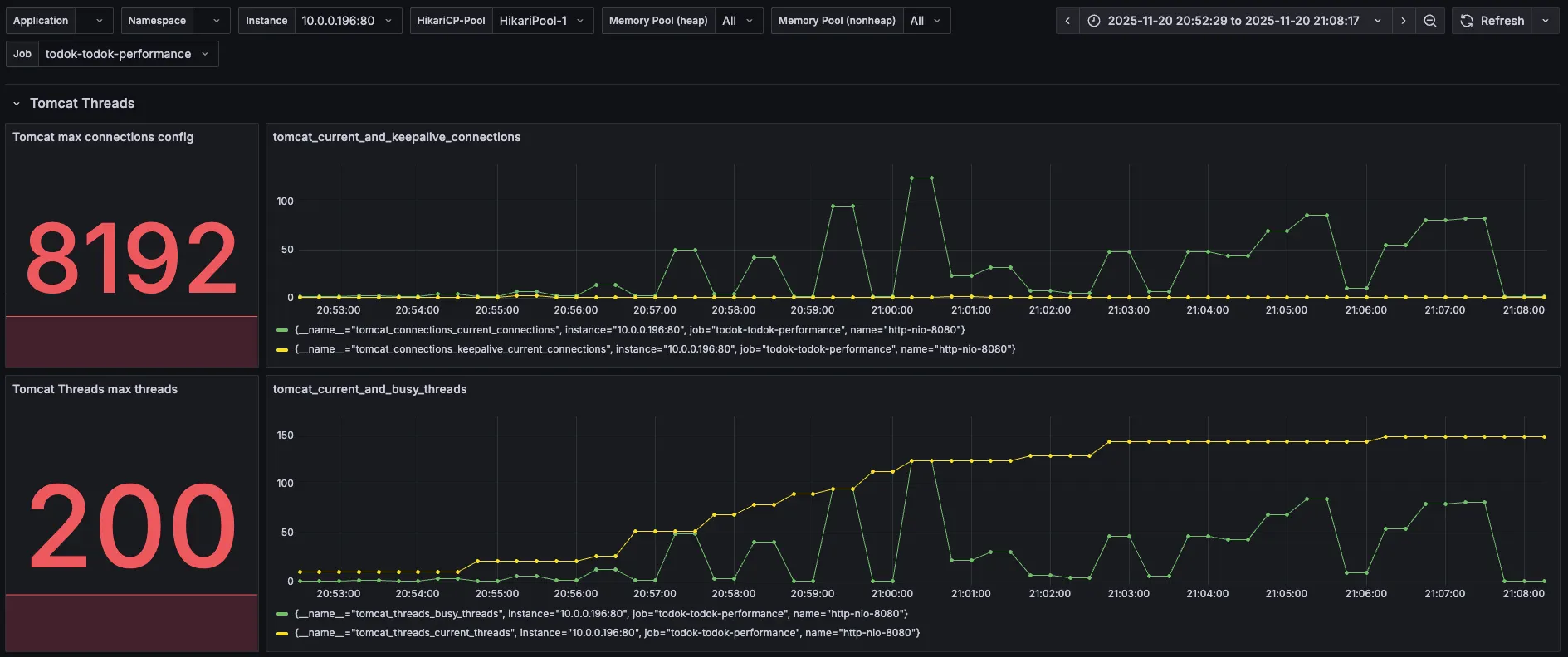
| 분류 | 직전 수치 | 현재 수치 |
| Tomcat max threads | 200 | 200 |
| current busy threads | 최대 150 근접 | 최대 124 |
| current threads | 최대 150 근접 | 최대 150 |
busy threads의 값이 많이 줄어든 것을 확인할 수 있었다. 하지만 여전히 current threads가 150 근처에서 지연되고 있다.
6. DBCP

| 분류 | 직전 수치 | 현재 수치 |
| Max Connections | 100 | 100 |
| Timeout Connection Count | 0 | 0 |
| Connections - Active | 88 | 88 |
| Connections - Pending | 60 | 35 |
| Connection Acquire Time | 최대 0.85 | 최대 0.06 |
커넥션을 얻기 위해 대기하는 Pending 수치도 많이 낮아졌고, Acquire Time도 굉장히 많이 줄었다.
하지만 여전히 DB 연결이 풀로 차있고, Active 숫자가 88에서 더이상 오르지 않고 있다.
7. CPU & I/O Time


드디어 CPU에서 특이점이 보인다.
갑자기 Sys Load가 엄청나게 뛰었다.
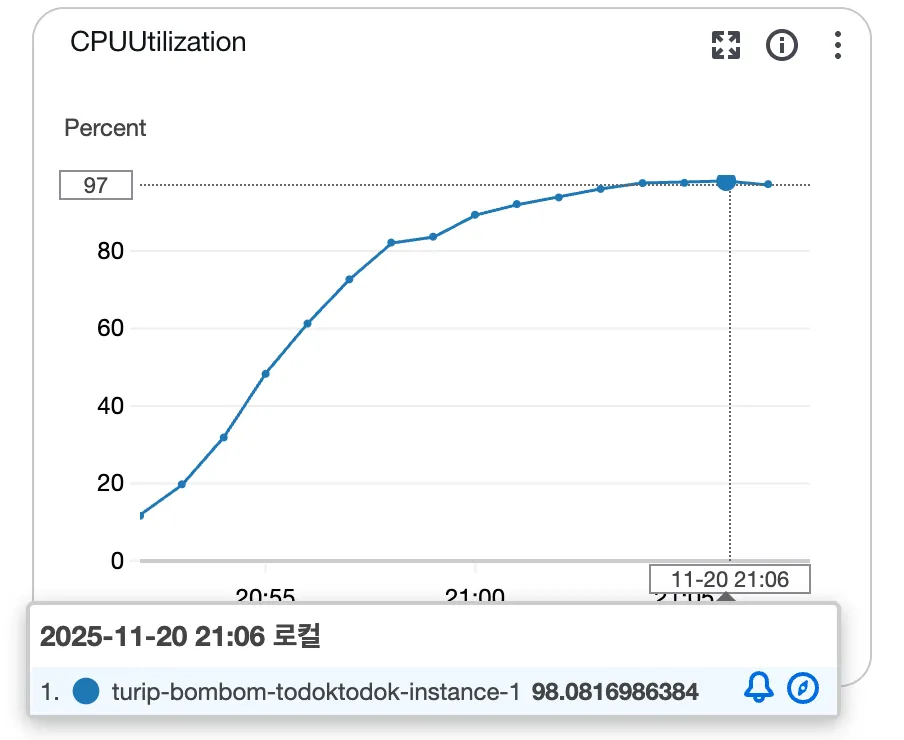
RDS DB 서버의 CPU 사용량도 확인해보니 순간 97%까지 치솟을 정도로 높았다.
DB 서버에서 발생하는 부하로 인해 WAS까지 이 부하가 전파된 것으로 생각된다.
8. API별 응답시간

| API | 분류 | 직전 수치 | 현재 수치 | 개선 비율 |
| 토론방 검색(/api/v1/discussions/search) | Avg (Max) | 6.90s | 2.50s | 63.77% |
| p95 (Max) | 10.6s | 4.16s | 60.75% | |
| p99 (Max) | 11.3s | 5.11s | 54.78% | |
| 인기 토론방 조회(/api/v1/discussions/hot) | Avg (Max) | 40.4s | 1.34s | 96.69% |
| p95 (Max) | 30s | 3.81s | 87.30% | |
| p99 (Max) | 30s | 4.21s | 85.97% |
응답시간이 말도 안되게 좋아졌다.
9. 결론 및 해결책
쿼리를 개선했는데도 DB 서버 CPU 사용률이 저렇게 높은 이유를 알 수가 없다..!
maximum-pool-size를 다시 한 번 조정해보도록 해야겠다.
마지막 편에 이어서!
https://ju-heee.tistory.com/69
내가 가진 색깔의 근거를 찾는 여정 - 하드웨어 스펙을 고려한 성능 테스트 진행기 4 (부하 테스
6~9차 부하테스트차수분류직전 수치바꾼 수치이유6차hikari maximum-pool-size100150Active 88 + Pending 35 = 총 123이므로 이 값보다 우회하도록 설정Tomcat max-threads200300DB pool size가 늘어났으므로 WAS가 여유있게
ju-heee.tistory.com
'study > 우아한테크코스' 카테고리의 다른 글
| 내가 가진 색깔의 근거를 찾는 여정 - 하드웨어 스펙을 고려한 성능 테스트 진행기 4 (부하 테스트 6~10차) (2) | 2025.12.03 |
|---|---|
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 2 (부하 테스트 1~3차) (0) | 2025.11.29 |
| 내가 가진 색깔의 근거를 찾는 여정 - 성능 테스트 진행기 1 (시나리오 수정, 스모크 테스트) (0) | 2025.11.28 |
| 2025 WOOWACON(우아콘) 후기 (2) | 2025.10.29 |
| 우아한테크코스 7기 백엔드 레벨2 회고 (0) | 2025.06.29 |